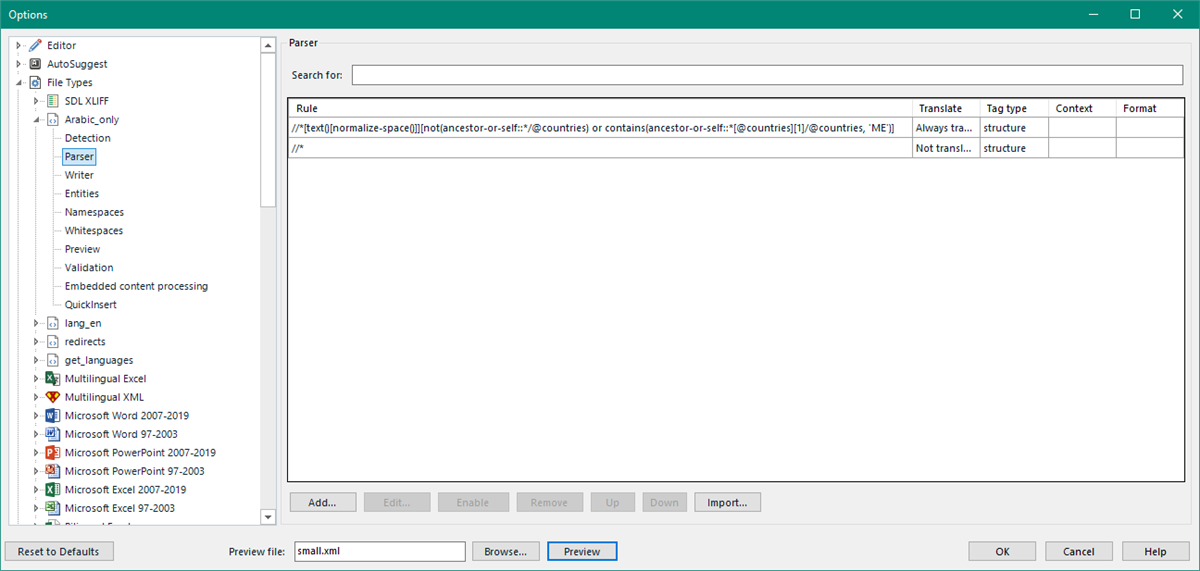
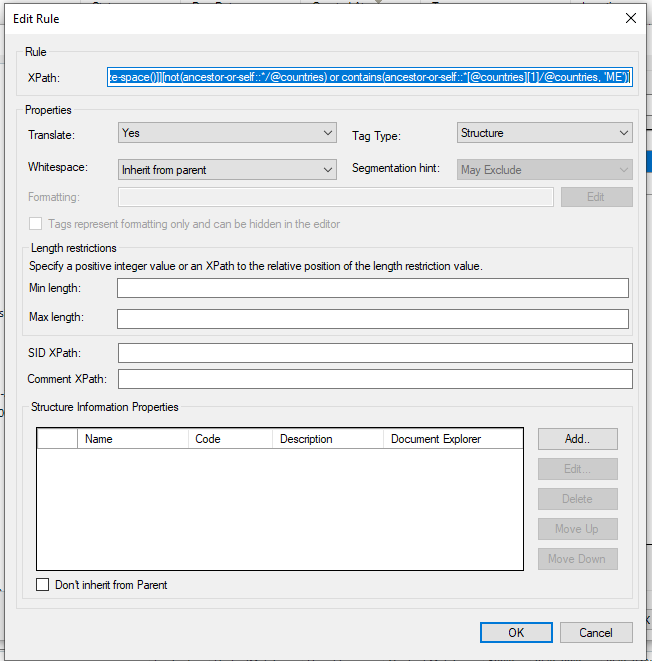
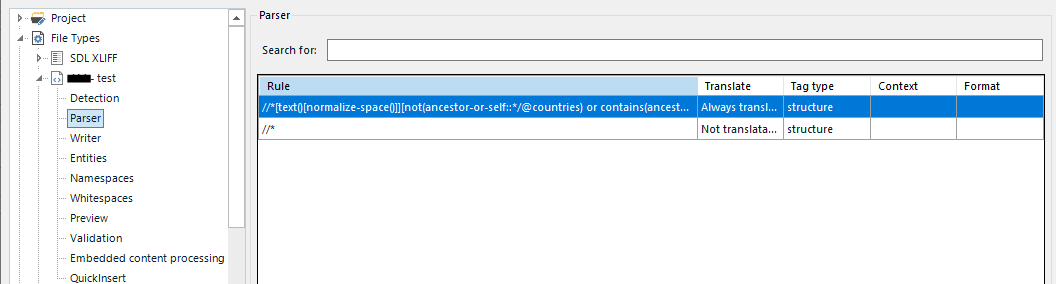
I have a bilingual XML file, is there a way of automatically excluding any text that isn't English from the source section when processing the file in Trados? It's currently a mix of Arabic and English in the source, and I only want to translate the English into Arabic. I could go through the file manually and lock all of the Arabic sections, but this is a really large file so would take too long, is there a way of doing this automatically/creating a setting that excludes the Arabic in the first place? Thank you!
I have SDL Trados Studio 2021 - 16.0.2.3343