


Please someone correct me if I am wrong, but I think the current documentation is misleading. If you follow it and create a custom batch task:
Pre-translate Files
Pre-translate Files with OpenAI provider
…you won’t get correct results.
Here’s why:
In the first step, TM matches and OpenAI run together. The AI translations are cached immediately.
By the time you run the second step, OpenAI mostly just reuses what was already cached. It doesn’t re-translate based on TM matches.
The correct approach is:
Run Pre-translate Files with only the TM enabled, using a lower fuzzy match threshold to catch partial matches.
Then run Pre-translate Files with the OpenAI provider. This way, OpenAI only translates segments the TM didn’t cover.
This ensures TM fuzzy matches are fully leveraged before AI fills the gaps.
Excerpt from documentation: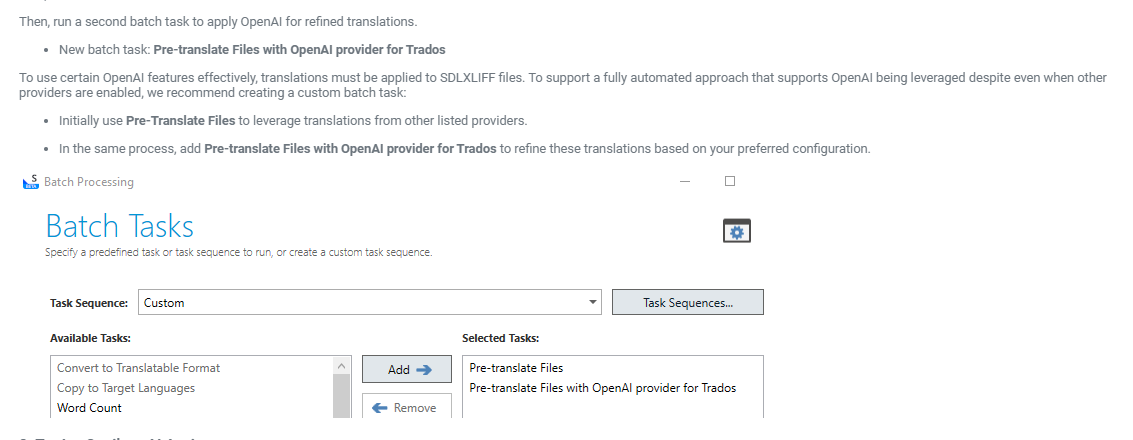
Generated Image Alt-Text
[edited by: RWS Community AI at 9:29 AM (GMT 0) on 24 Mar 2026]

