
Direct PDF (using PDFLib) is playing a more and more important role in XPP.
Some new features are only available through the use of Direct PDF.
Direct PDF is the preferred future output method for XPP.
It is great but not very friendly when you are confronted with an error somewhere at output time.
But since the whole PDFlib thing is almost completely detached from compose, debugging errors is difficult.
Most of the possible errors involving things like tagged pdf, bookmarks, annotations will not be detected during compose.
These errors will only pop up when you effectively run the divpdf command.
And that makes it almost impossible to detect where exactly the error is on the page or even within the job.
Lets have a look at a sample job I happen to notice an error in.
This is what I get when I do the print from pathfinder: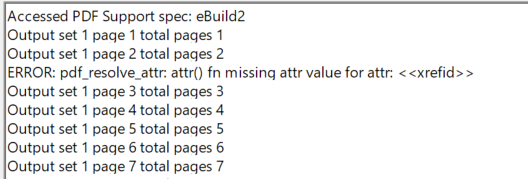
This might lead you to believe that the error is on page 2
But when you run the divpdf command from the terminal you get:
So the error is somewhere on page 1.
But where?
Well there is the good old PDF Check command that you can run, but this will only check the PDF marks that are set through PostScript and this does not check the new features available through Direct PDF.
So this what I get when I run the PDF Check command:

So here I am, I have a PDF that has an error but I have no means to detect where that error is.
Ah you will say, but there is the -dump option you can add to the divpdf command. This will create a file called divpdf.log file containing all command issued to the PDFlib product that is used by XPP.
Unfortunately this log file will only contain error detected by the PDFlib product.
And in my case the error is emitted by the XPP layer that drives the PDFlib product.
So here is my proposal:
Please add yet another option to the divpdf product (maybe something like -log) that will create a log file containing all the calls send by the XPP layer to the PDFlib product + all errors that might occur.
This way we might be able to detect exactly which of the calls contains the error.
