
We are trying to see how much fuzzy matches are changed by linguists. It would be beneficial to call out match types in the filtering for initial translation origin.
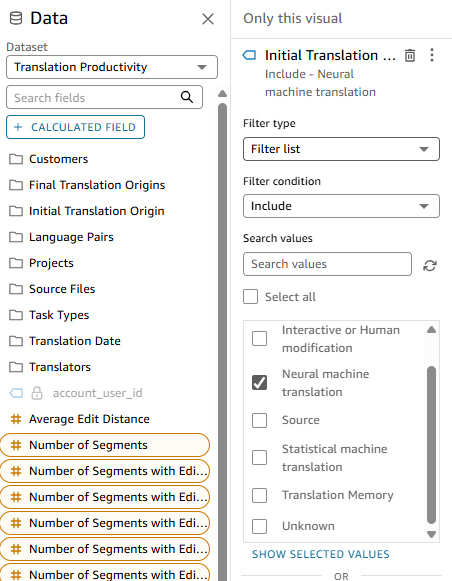
We are trying to see how much fuzzy matches are changed by linguists. It would be beneficial to call out match types in the filtering for initial translation origin.

Top Comments