
I am not a big fan of adding fancy complex XPath parser rules that make XML file type settings fairly difficult to read.
Nevertheless, I think that the default DITA parser rule that defines all XML nodes of this type //*[@translate='no']
as structural leads to both segmentation issues and nesting of structure elements inside inline elements.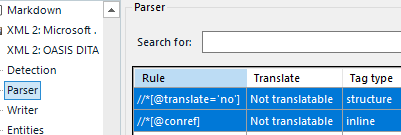
This should be avoided by adding an extra parser rule to the default DITA file type settings.
The inline parser rule would need to look a bit like the following://*[@translate='no'][ancestor::*[child::text()[string-length(normalize-space(.)) > 1]]]
This way, if a non-translatable element occurs in mixed content (containing both elements and text nodes),
the element would automatically be declared inline.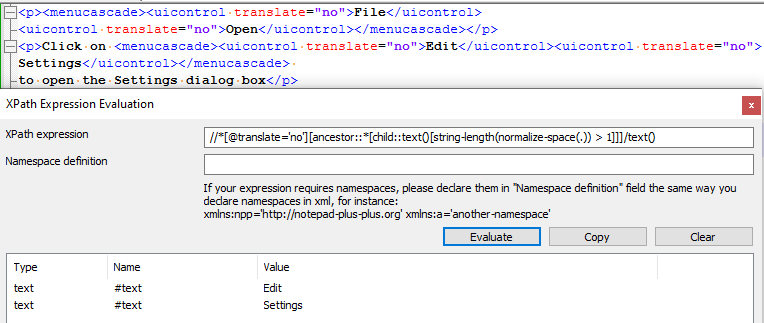
By the way, the same seems to applies to the parser rule: //*[@conref]
RWS Community

Top Comments