


How do we change Studio 2019 QA settings so it does not report a "space" in draft translation as error?
RWS Community
How do we change Studio 2019 QA settings so it does not report a "space" in draft translation as error?
I discussed this with the development team and this is apparently by design. The phrase "Forgotten and empty translation" apparently includes segments that only have spaces in them. So this one:
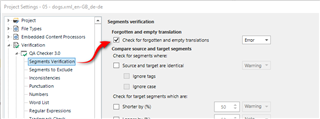
Having said this the team are willing to listen to whatever reasoning there is for why the behaviour shouldn't be this way. So if you have some real examples of when you would want to have a space in the target segments, and perhaps even the usecase and solutions you use to get them in there, then it would be very useful to hear them.
Copying a couple of people I think have done this in the past...
Paul Filkin | RWS
Design your own training!
You've done the courses and still need to go a little further, or still not clear?
Tell us what you need in our Community Solutions Hub


Hi Paul Filkin, Elevate Autumn 2021,
I see why you're asking for comment. It's currently an 'all or nothing' situation. You can't check for forgotten or empty translations without also having segments flagged up where a space has been inserted to prevent the source content flowing into the target document. This is indeed something I do, for example where the only content of the source segment is the German verb at the end of a sentence that has been unchangeably auto-segmented by a client database, and I want the full stop to be at the end of the previous segment because the verb is not at the end of the English sentence and a merge is not possible.
When I receive a proofreading job this box is ticked in the agency's required project settings so I just cope with it rather than untick it and risk missing an untranslated target segment that the translator or I might have accidentally deleted or left empty.
Interestingly, the above setting also picks up, for example, just a full stop.
In some formats, it is a problem when a sentence has been segmented with content that HAS to be translated in each segment of the sentence because it is present only once in the SDLXLIFF but repeated in further instances in the final database-generated PDF document. This happens, for example, in imported bilingual .xlf format and translators really don't want to jump through hoops so that the verb remains in that segment, but ideally I have to rewrite the sentence in a clumsy way to achieve that if possible, so that the end client's database doesn't contain and repeatedly generate an incorrect translation... I hope I'm explaining myself intelligibly...
I for one would be pleased if there were a second tick that allowed to ignore a space or a full stop, for example. However, it isn't essential to life 
Thanks and all the best,
Ali 

Thanks Alison Field, that's helpful. Tagging a couple of interested parties in case of questions.
Paul Filkin | RWS
Design your own training!
You've done the courses and still need to go a little further, or still not clear?
Tell us what you need in our Community Solutions Hub
Thanks Alison Field, that's helpful. Tagging a couple of interested parties in case of questions.
Paul Filkin | RWS
Design your own training!
You've done the courses and still need to go a little further, or still not clear?
Tell us what you need in our Community Solutions Hub
Hi all,
There is a simple workaround to prevent segments with just a space from being flagged up when the QA "Forgotten and empty translation" box is ticked:
Display filter for ^\s$
Click in the top left corner to select all
Ctrl+L to lock all these segments
Then tick 'ignore locked segments' in the QA settings
Job done!
Ali
Thanks Alison Field, helpful as always. The most important part you answered earlier which was why do users want to do this?
where a space has been inserted to prevent the source content flowing into the target document.
Is this the only reason for this usecase? It is a good one, but just checking :-)
Paul Filkin | RWS
Design your own training!
You've done the courses and still need to go a little further, or still not clear?
Tell us what you need in our Community Solutions Hub
Hi Paul, hi Jerzy Czopik
This is the most frequent usecase in my experience. Jerzy, I don't use 'sign-off rejected' unless the agency requires it, I just lock the segment as 'translation approved'. The agency also requires that I return the file they sent me to work on, or with one that will work with the project at their end.
I have to ask permission to use the edit source feature, unless it's a format such as Word where it will trigger no problem when converting back to original format. In every case, the end file will be a 3rd party's property and the agency need it to run smoothly for the end client as well.
More and more content is generated by end client (3rd party) database or, for example, cosima. In my case, bilingual .xlf or .xml-based projects. One has to be careful to stick to methods that won't cause issues for the end client's software. I've learned what does and does not work over the years of working with these formats, I'm sure you have too, Jerzy. In these and other context such as .idml, there is often background content that cannot be seen even with the All content display filter set. It can be vital to stick to the segmentation that is generated to avoid accidentally preventing the background content 'flowing back' correctly to the original format.
It must be so hard for new translators cope with these scenarios. I understand them all because I've worked with them and with Studio and TagEditor before Studio so have a decade and a half's experience, as do you of course.
I'll think about other usecases later as there must be many, Paul, but have to go out now...
Great to chat!
Ali

You are completely right with all the possible segmentation issues. However, I do not ask for permission, but only make sure the file works. Asking for permission is simply too time consuming in our deadlines world 
_________________________________________________________
When asking for help here, please be as accurate as possible. Please always remember to give the exact version of product used and all possible error messages received. The better you describe your problem, the better help you will get.
Want to learn more about Trados Studio? Visit the Community Hub. Have a good idea to make Trados Studio better? Publish it here.
Same here really in practise...
Have an excellent afternoon/evening!
Ali
Hi again Paul Filkin
It could be that this question and/or the other were asked because the end client does not wish to see false positives in their final verification...?
Probably overthinking...
Ali
Could be, but I'm afraid this is "Milchmädchenrechnung", as regardless what you set up, there will always be some false positives in the automated QA. From my experience it is simply impossible to have a setup, where no errors are reported even if there are really no errors. For example it might be a missing or added punctuation mark, because your target language needs that for a list. Or a different capitalization, which happens more than often when translating from German. Or it will be different spacing around tags. Or many more...
_________________________________________________________
When asking for help here, please be as accurate as possible. Please always remember to give the exact version of product used and all possible error messages received. The better you describe your problem, the better help you will get.
Want to learn more about Trados Studio? Visit the Community Hub. Have a good idea to make Trados Studio better? Publish it here.
"Milchmädchenrechnung" I like it! "Over-egging the pudding" is an English idiom that springs to mind...
Indeed, it's impossible to never generate false positives. One has to learn which of them one can ignore or the verification ends up taking longer than the translation