

Thank you for writing the OPUS-CAT MT plugin! It is great.
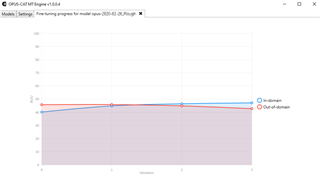
I have a question regarding the graph that shows fine-tuning progress... how do I read it? Sometimes I get lots of "validation" data points, sometime, like in the model below, it's just a few. Why? And what is "in domain" and "out of domain"?
As for EN-DE translations, after training the model using my existing TMs, the results are great. The one drawback is that the system does not handle tags at all, but the translation quality is very good if the text is not too complex (in which case DeepL still has better results). I am impressed by its use of custom terminology in the TMs used for training.
So thanks a lot. If you intend to have a German version of your web pages or UI, I would be happy to help.
Daniel

