What is Robots.txt, Purpose and it's Usage:
Web site owners use the /robots.txt file to give instructions about their site to web robots; this is called The Robots Exclusion Protocol.
It works like this: whenever a robot wants to visits a Web site URL, say http://www.example.com/welcome.html. Before it does so, it firsts checks for http://www.example.com/robots.txt, and finds:

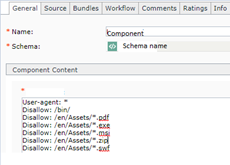
The "User-agent: *" means this section applies to all robots. The "Disallow: /" tells the robot that it should not visit any pages on the site.
There are two important considerations when using /robots.txt:
- Web Robots (also known as Web Wanderers, Crawlers, or Spiders), are programs that traverse the Web automatically.
- robots can ignore your /robots.txt. Especially malware robots that scan the web for security vulnerabilities, and email address harvesters used by spammers will pay no attention i.e. Search engines such as Google use them to index the web content, spammers use them to scan for email addresses, and they have many other uses.
- the /robots.txt file is a publicly available file. Anyone can see what sections of your server you don't want robots to use.
Tridion Implementation:
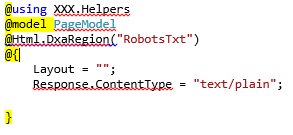
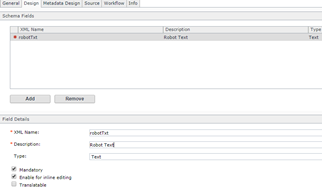
- Create a new Schema with Text Field (mandatory) and Create Model for the same to render in DXA, While creating the component make sure to add the all the rules i.e. (in text field ) sample e.g.:
Schema: Component: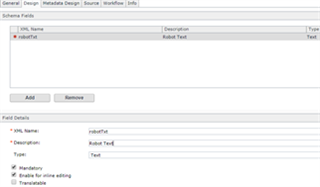
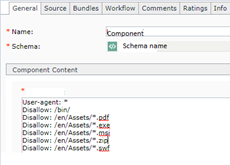
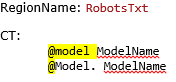
- Create a Region and Component Template
- Create a Page Template and i.e. ready to use the same in the Page.