



"High Availability" in the wider world
The concept of "Availability" came way before and is not limited to computer systems. We all know the following examples
- A football team has players on the bench
- An airplane has multiple engines
- Nuclear plants have multiple cooling stations
- You have 2 eyes, 2 ears and 2 kidneys
Without further explanation, apparently the concept of "Availability" is that in the event of one component fails, the whole system is still functional.
Why do you/do you not need High Availability
SDL Web is a Content Management System in its core. While the availability is important, it is an entirely different industry from the ones that are safety-critical such as an airline controlling system. The word "High" is relative here and honestly, relatively low in a grand scale.
With that in mind, everyone using SDL Web does have different availability requirements. The imaginary examples below give some ideas (your exact situation would be different so please do not use these as a standard),
On a website level
- S1: My personal blog (99% availability - I can bear with the site being down for a day per 100 days)
- S2: An informational home page that displays a banner and company's latest news (99.9 availability - well, roughly 10 minutes per week down-time was accpetable to the company owner)
- S3: A e-commerce site's checkout pages that offers purchasing a high-value product (99.99 availability - that is about 1 minute per week - what is the chance that the checkout happened at this minute?)
- D1: A deployer used by the company's corporate site to publish updated office locations (90% availability - editors may get frustrated, but in reality the new office manager thinks it is no big deal to delay the office location update for a few days.)
- D2: A deployer used by a news agent to regularly publish breaking news (95% availability - I want to be the first to publish the latest news, but I am no BBC or CNN)
- D3: A deployer used by an international corporate to publish their quarterly and annual result (99.995% - stock market opens at 8am, and I will start publishing results at 7am. If I can't get the result live by 7.30, I will be in big trouble. I won't die but will want to)
Finally on the Content Manager level
- C1: I update my personal blog space once a month (less than 90% availability is fine)
- C2: A local company with their UK content editors working 9-5 every weekdays (95% availability - as long as IT is available to fix the problem when an important piece of content needs to go out)
- C3: A global company with their content editors across the world working around the clock (99% availabilty, but again, we need someone technical's infrequent support for important and urgent content input should anything fail)
So realistically, how "available do you need to be"? It firstly largely depends on the cost of unavailability. The cost can be both monetary in terms of not being able to finish the transaction, or cost of company's reputation, time to fix the failure, opportunity cost of not being able to convert a site visit to a Salesforce prospect, and so on. Also, the higher availability you want to achieve, the higher the cost is for the extra hardware/software, the cost of maintenance and the availability of professionals needed for the set up and operations of such systems.
Measurements
Up/Down times (or 9's),
As shown in the above examples. 99.99% uptime equals to "four 9's" availability and it means the system is down 1 minute per week in average. Once we get these unavailability figures for each component, with some simple maths we will have the unavailability for a system combining a number of sequential or parallel components.
Mean Time Between Failures (MTBF),
MTBF measures the average up time from the end of each down-time and the beginning of next downtime. It is an important measure, in that through existing reliability formulas, we can calculate the probability of system failure at a given length of time. I will skip the math but to give an example, if MTBF of something is 1 year, the probability of it surviving 1 year without failure is a mere 36.8%
Mean Down Time (MDT),
MDT measures the average downtime of the system. Importantly it does not only include the time to fix the failure, but also includes the time lapsed before being notified of the failure, and the time to get an engineer ready to perform the diagnose and fix.
Calculations and Conclusion
Finally, with their individual MTBF and MDF values, we can calcuate the MTBF and MDT values if the system contains a number of sequential or parallel components. Again I will skip the math bit but just list the formula below
Two parallel components:
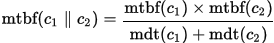
Two sequential components:
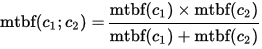
Our goal is to
- Increase the system MTBF so that a planned maintenance has sufficient time to kick in.
- Decrease the system MDF before stakeholders and users get upset (or even noticed)
- When MDT of each component is reduced sufficient enough to be much lower than its MTBF, the entire system's MTBF will be much longer when the components work in parallel than when they work in sequence.
- When 2 components are working in sequence, the system's MTBF will be lower than individual component's MTBF. A special case is that if two sequential components have the same MTBF, the MTBF of the system is only half of that.
Then came in Parallel Working - Clustering and Replication
To increase indiviudal component's availability, clustering is to put multiple same components in a cluster working in parallel. When one component fails, as other components are still functional, the entire system will not be down. For all components to function in same/similar way, replication is needed for them to have the same or very close state or data.A higher availability through clustering can usually be acheived in two ways,



