Summary (The Problem)
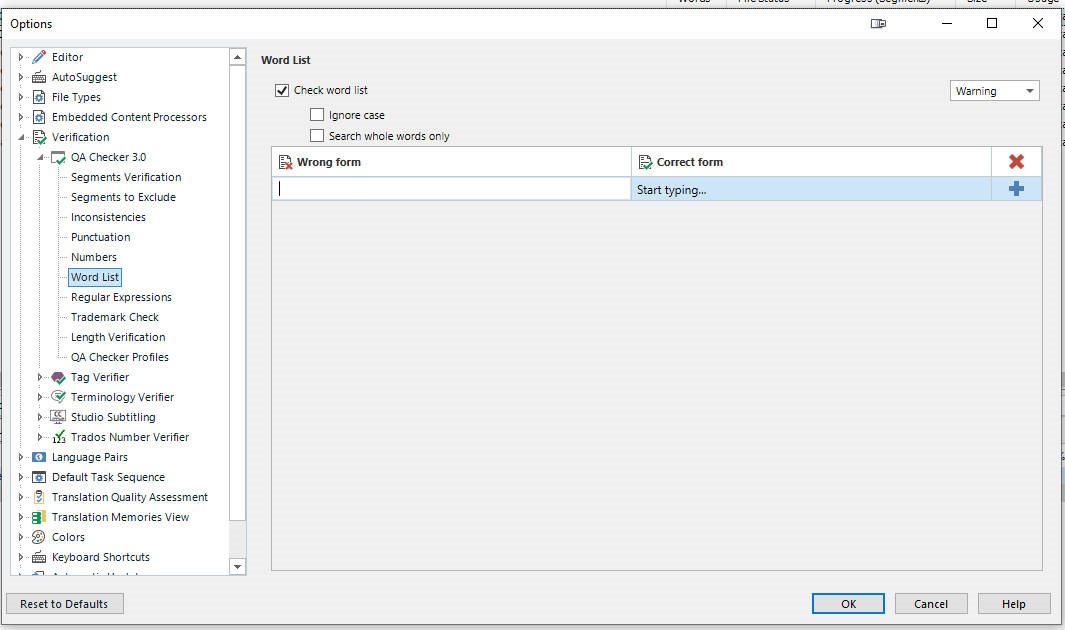
Currently, the "Word List" feature within the QA Checker 3.0 (accessible via Options > Editor > Verification > QA Checker 3.0 > Word List) requires users to manually type every single "Wrong form" and "Correct form" entry one by one.
For linguists and project managers dealing with large projects, inconsistent client terminology, or specific market preferences (e.g., Arabic with Latin script variants, or regional differences like "color"/"colour"), this manual process is a significant productivity killer. It forces users to engage in tedious, error-prone data entry instead of focusing on translation quality.
Furthermore, the current logic lacks flexibility. As demonstrated in the example below, it cannot handle scenarios where a "wrong" term is a substring of a valid "correct" phrase.
Proposed Solution
I propose two major enhancements to the "Word List" feature:
1. Import/Export Functionality (e.g., via Tab-delimited .TXT, .CSV, or .XLSX)
-
Allow users to Export the current list to a file for backup or editing in Excel.
-
Allow users to Import a list from a file.
-
Benefits: This would allow users to maintain large lists externally, use Excel formulas to generate pairs, and share lists across teams without manually re-typing thousands of entries.
2. Advanced Matching Logic (Regex Toggle)
-
Introduce a checkbox next to each entry or a global setting to "Enable Regular Expressions" for specific word pairs.
-
Benefits: This would allow for context-sensitive checks, preventing false positives where a "wrong form" appears as part of a larger, valid "correct form."
Use Case / Example (Arabic Terminology)
To illustrate why these features are essential, here is a real-world example based on Arabic translation variants.
-
The Scenario: In some Arabic locales, the month "January" is written as
يناير. In others, it is written asكانون الثاني. A client might require the formatيناير/كانون الثانيto appear in the text. -
The Goal: We want the QA to flag instances where a translator has written
ينايرalone (as a standalone word) but ignore it when it appears inside the valid combined phraseيناير/كانون الثاني.
Why the Current System Fails:
If I manually add the pair:
-
Wrong form:
يناير -
Correct form:
يناير/كانون الثاني
The QA will flag every single instance of يناير as an error, even if the sentence contains the correct phrase يناير/كانون الثاني, because the string "يناير" exists within the longer string. This creates noise and forces the user to ignore valid errors.
How the Proposed Solution Fixes It:
With the Import/Export feature, I could prepare a spreadsheet with hundreds of these regional pairs in seconds.
With the Regex feature, I could refine the rule to only catch the wrong form when it stands alone:
-
Wrong form:
\bيناير\b(?!\/) -
Correct form:
يناير/كانون الثاني -
Explanation: The regex
\bيناير\b(?!\/)looks for the wordينايرwith word boundaries (\b) that is not followed by a forward slash (i.e., it is not part of the combined form). -
Result: The QA would correctly flag the error if the translator writes just
يناير, but ignore it if they write the desiredيناير/كانون الثاني.
Business Value
-
Time Savings: Eliminates the need for manual data entry for large lists.
-
Accuracy: Reduces typos introduced during manual entry.
-
Scalability: Allows project managers to handle complex terminology rules (like the Arabic example above) that are currently impossible to automate via the GUI.
-
Integration: Fits perfectly into existing translation workflows where terminology is often managed in spreadsheets.