Hi all,
I have 2 inherited files that have their origin in the computational Middle Ages (Fortran, punch cards -- really!) and look like this:
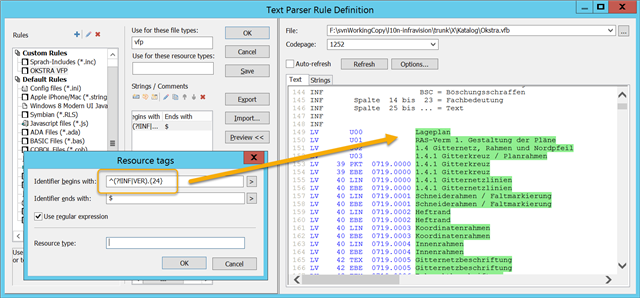
INF
INF
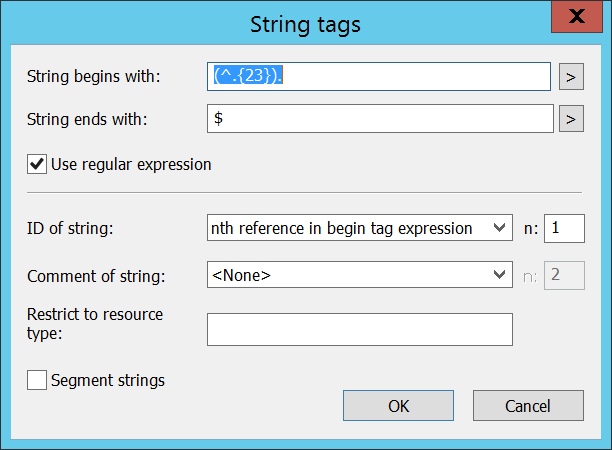
INF Spalte 10 bis 12 = Darstellung
INF Uxx = Überschrift
INF PKT = Punktdarstellung
INF LIN = Liniendarstellung
INF FLA = Flächendarstellung
INF TEX = Textdarstellung
INF EBE = Speicherebene
INF FBM = Fahrbahnmarkierung
INF BSC = Böschungsschraffen
INF Spalte 14 bis 23 = Fachbedeutung
INF Spalte 25 bis ... = Text
INF
INF
LV U00 Lageplan
LV U01 RAS-Verm 1. Gestaltung der Pläne
LV U02 1.4 Gitternetz, Rahmen und Nordpfeil
LV U03 1.4.1 Gitterkreuz / Planrahmen
LV 39 PKT 0719.0000 1.4.1 Gitterkreuz
LV 39 EBE 0719.0000 1.4.1 Gitterkreuz
LV 40 LIN 0719.0000 1.4.1 Gitternetzlinien
LV 40 EBE 0719.0000 1.4.1 Gitternetzlinien
LV 40 LIN 0719.0001 Schneiderahmen / Faltmarkierung
LV 40 EBE 0719.0001 Schneiderahmen / Faltmarkierung
LV 40 LIN 0719.0002 Heftrand
LV 40 EBE 0719.0002 Heftrand
LV 40 LIN 0719.0003 Koordinatenrahmen
LV 40 EBE 0719.0003 Koordinatenrahmen
LV 40 LIN 0719.0004 Innenrahmen
LV 40 EBE 0719.0004 Innenrahmen
LV 42 TEX 0719.0005 Gitternetzbeschriftung
LV 42 EBE 0719.0005 Gitternetzbeschriftung
These files get written to (lousy serialized XML) at run time and trying to align these XMLs was ... not funny.
One file is 75,000 lines, the other 50,000 lines.
So my question would be: can Passolo deal with a format that basically says "treat everything starting at character position 25 to line end as text"?
Any help that would save me from making an XML Diff of these files in order to align the existing translations would be VERY MUCH aprreciated.
Greetings,
Franz-Josef