Dear Community,
this post is an inquiry aimed at understanding better what new Trados24 version brings.
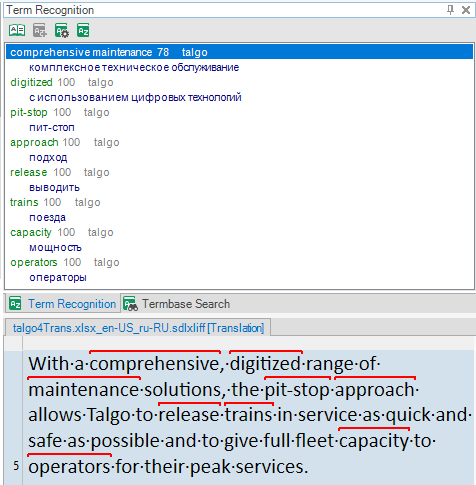
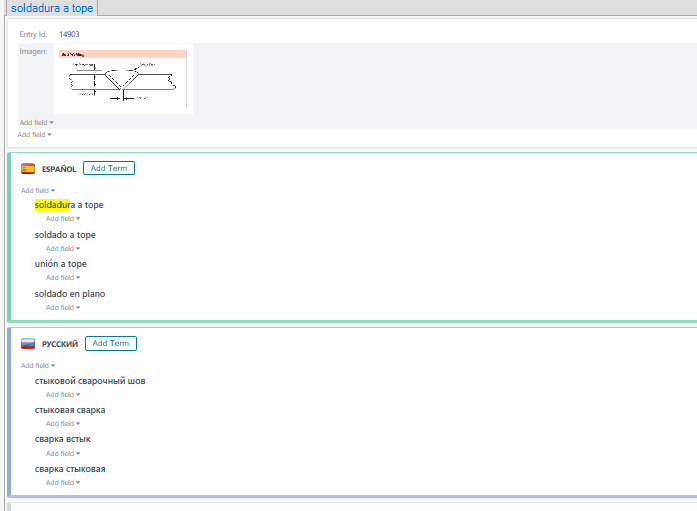
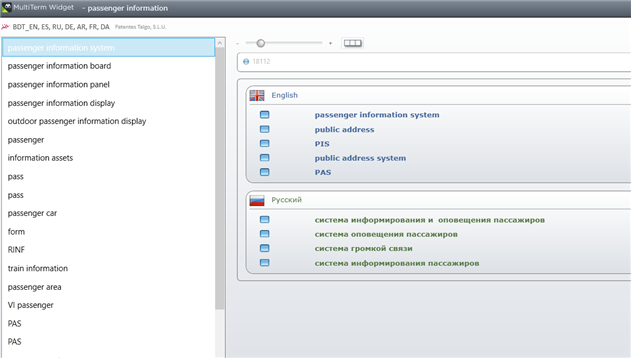
Here is a curious example of term recognition performed by Multiterm today:
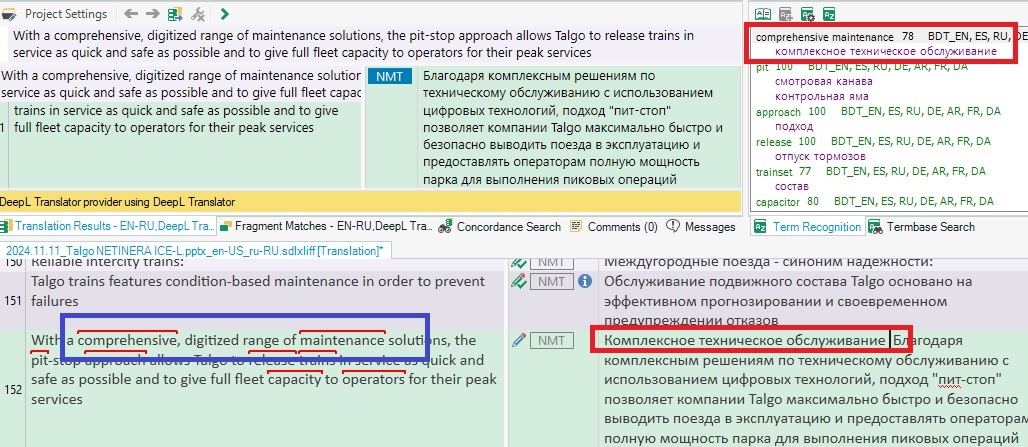
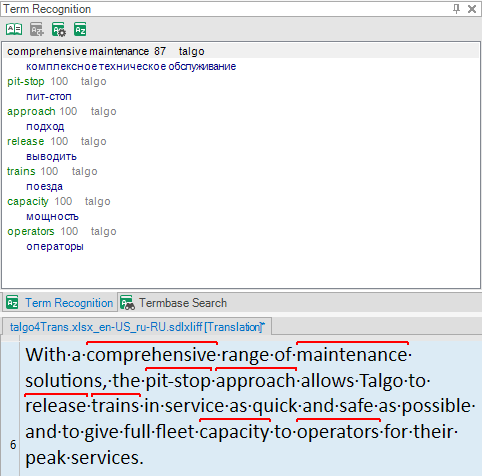
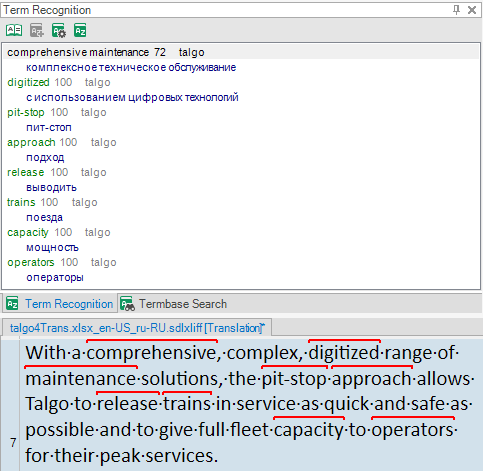
I have NEVER seen Trados recognize separate words as part of a term saved in the database (comprehensive and maintenance, in this particular case).
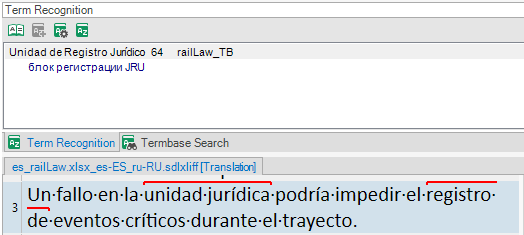
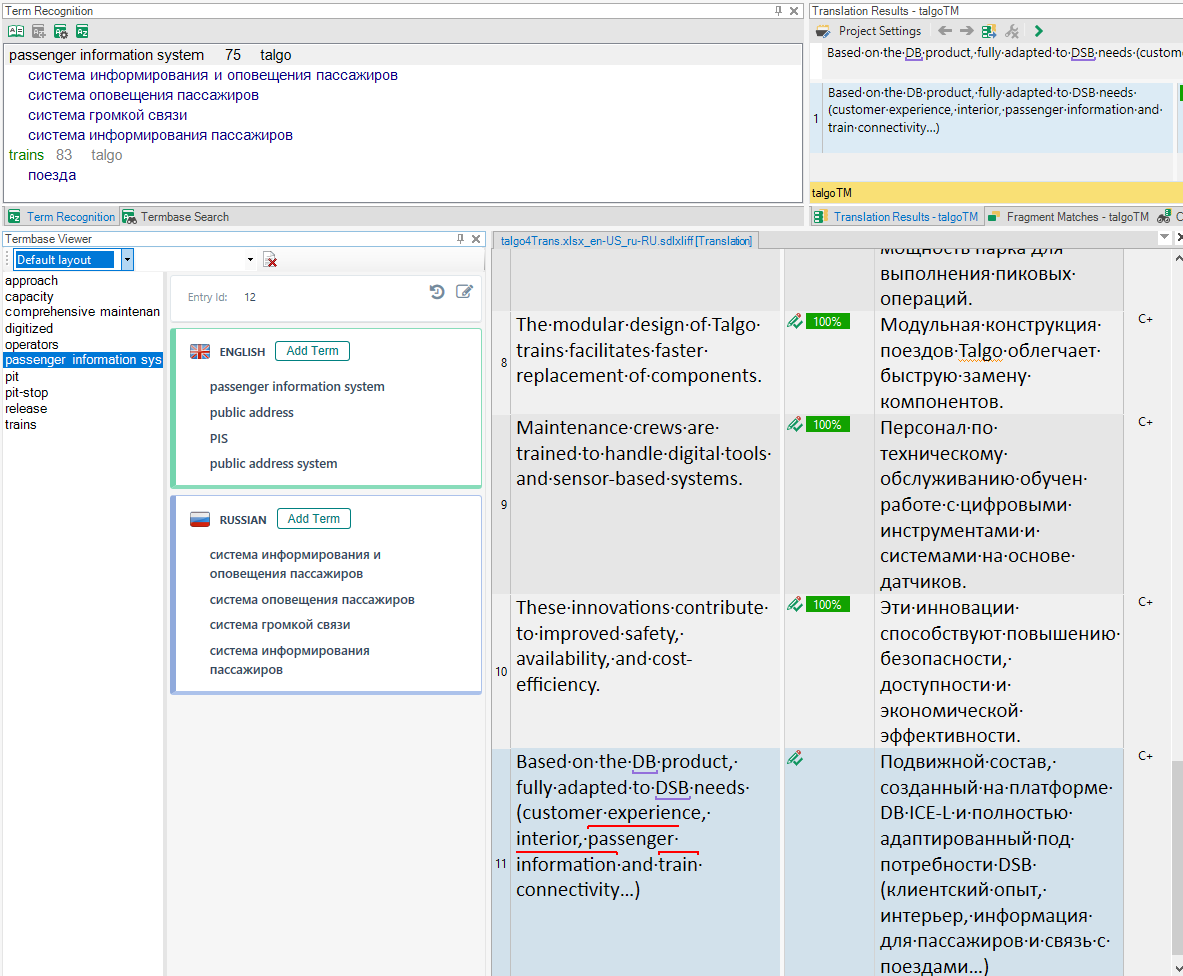
The search is set to 70%, which is a standard issue:
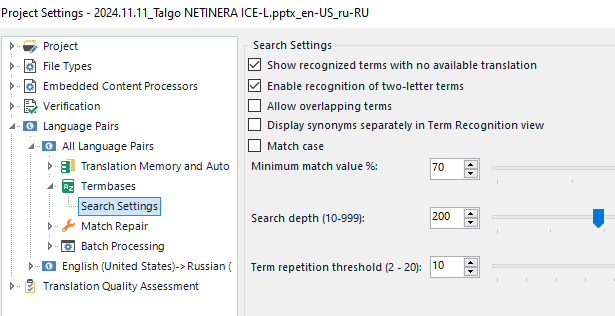
First, I thought that Multiterm recognized only "comprehensive" and returned a fuzzy match from the database (even this would be a 50-60% match, definetely not 70%, in my opinion).
But then I saw that "maintenance" does not appear in the hitlist as a separate term, meaning that both words were recognized as parts of "compehensive maintenance". How come? There are 3 words inbetween!
This has never happened in the previous versions. Is there any technical explanation? New search processes in Trados 2024?
Would be very grateful for the explanation! Thanks in advance!
Generated Image Alt-Text
[edited by: RWS Community AI at 8:09 AM (GMT 1) on 2 Apr 2025]