Hi everyone,
I'd like to update some (massive) TMs, but I don't know which source files have already been aligned and added, so that's the first item on my to-do list before adding any new alignment result.
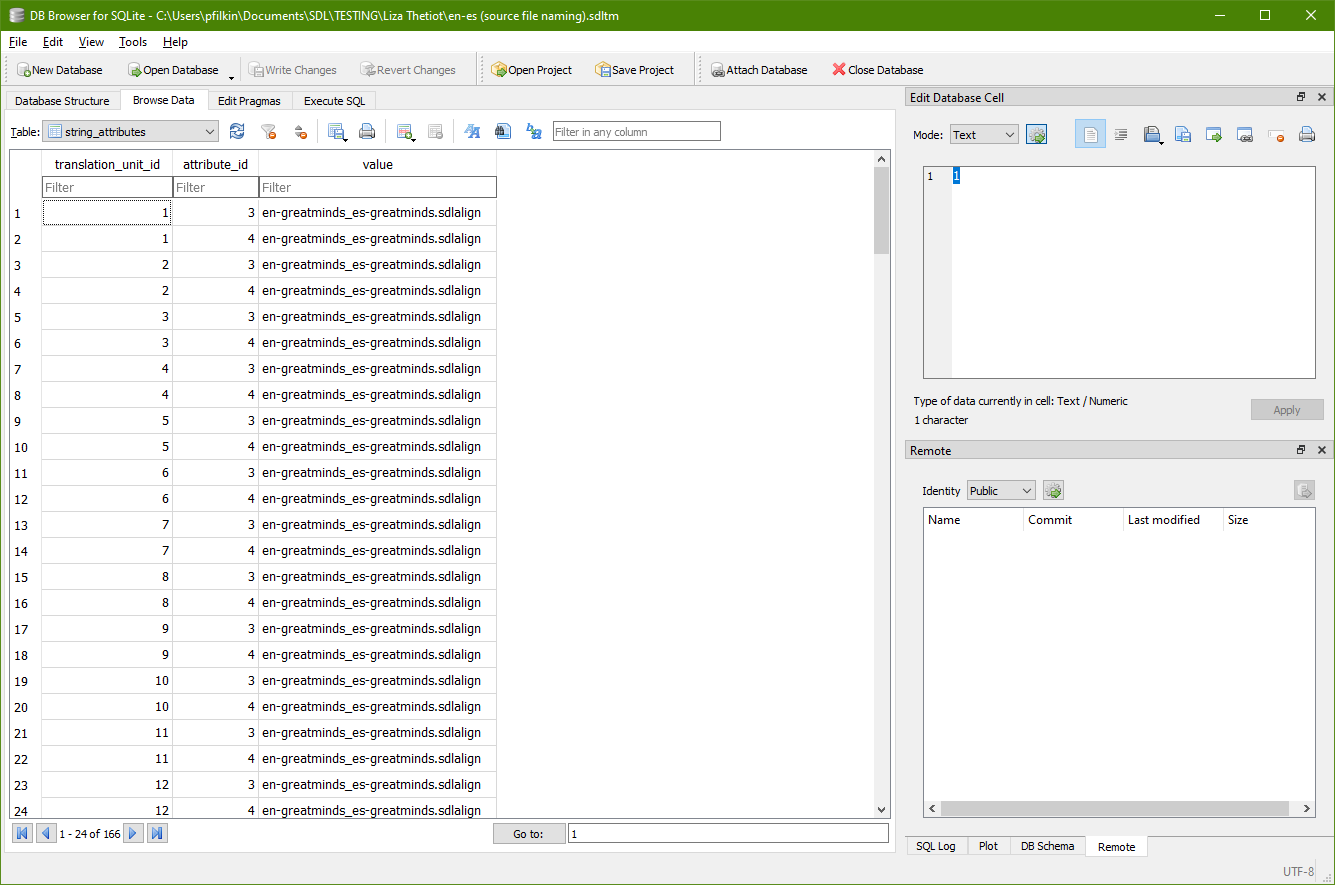
So far the only way I've found is to simply open the TM in Trados, look at the third column and copy/paste the source file name somewhere.
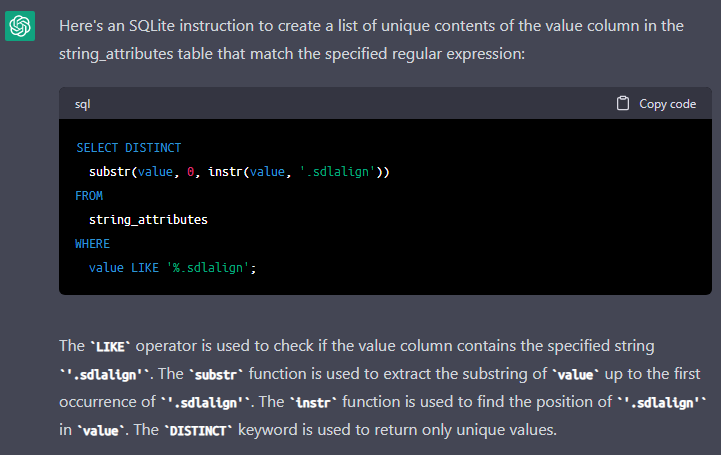
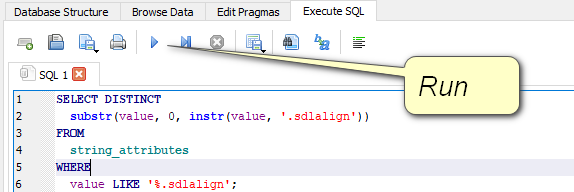
Is there any automated way to get the list of all the source files in my TM? I've thought about SQL-ing this, but I don't know enough about it.
Any help would be greatly appreciated! Thanks!