


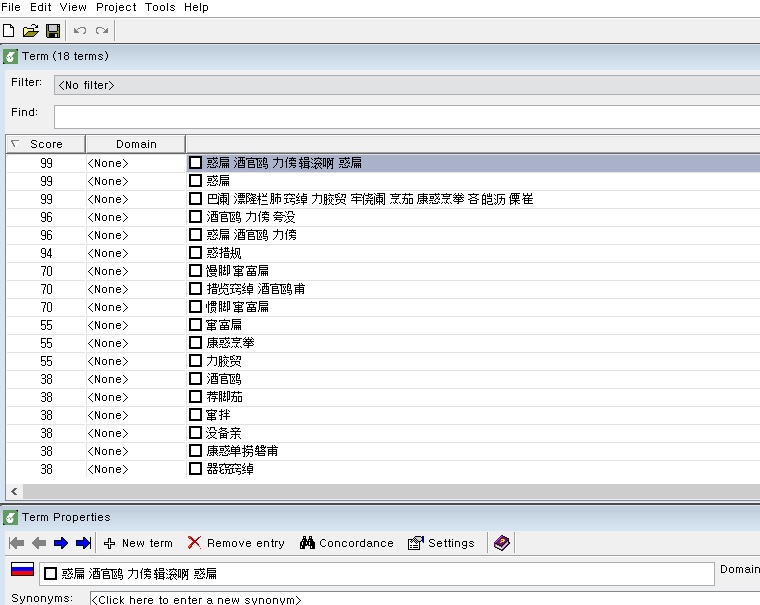
I want to extract terms from a Russian document by using Monolingual Term Extraction Project.
But as you can see in this picture, the extracted terms appear in the incorrect form.
Ironically, I can successfully extract terms from a document written in English.
I suspect SDL Multiterm Extract has problem extracting terms from non-us documents (e.g. Korean and Japanese)
And when I try to extract terms from .txt files, I just see the program come to a halt.
Please let me know how to solve this issue.
Operating System : windows 10 Korean
Project File: russian.doc (created by Microsoft word 2016 Korean)
