I have 2 problems regarding Term recognition on Trados Studio 2017.
Please teach me how to solve these problems.
I changed some settings regarding term recognition on the project.
After that either of 2 problems occurs.
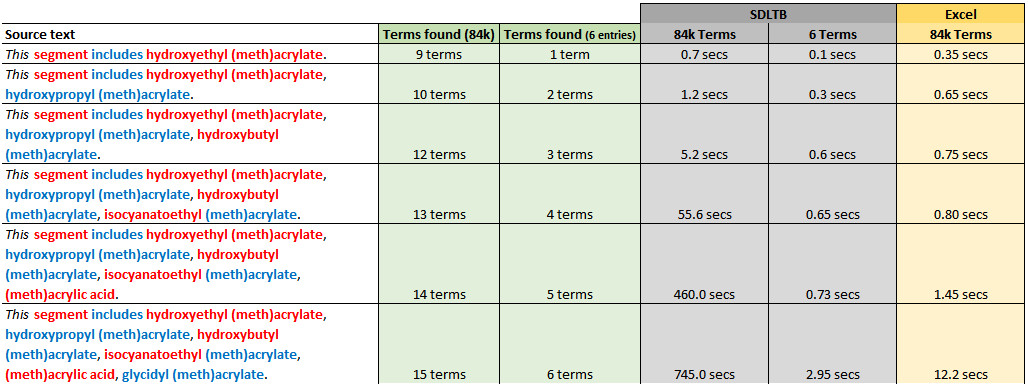
First one is that the displayed message "Searching for terms" is kept on the Term recognition screen for more than 5
minutes.
Second one is that when next segment is selected after recognized terms are displayed by waiting for long time,
screen inside the Term recognition is not refreshed!
TM seems to be recognized sooner than Termbase.
I guess some changes in the project affects adversely to searching terms.
But I do not know which change(s) cause these problem.
Alternatively any other factor may cause these problem.