


Hi there,
hope this is a problem someone of you can help me with. I have an IDML file (606 KB) from which I would like to extract terms with MultiTerm Extract 2017, but the file cannot be processed somehow. I have tried converting it to HTML and XML, the programme then imports the file, but when I click on "process" there is an error saying that the file cannot be read.
I've noticed that a few of the available supported file formats like DOC, TXT, ISC, etc. are missing (see screenshot).
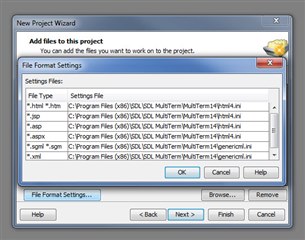
Would anyone know how I could get those options into the programme? Then I could convert the file to TXT, ISC or DOC and maybe then it would work.
I don't have the TagEditor of Trados though...
Many thanks in advance for your help!

