I'm testing Trados for Tibetan translation and I'm trying to get a proof of concept for using a Tibetan termbase. It seems I cannot get any term recognition for a Tibetan source text. I create a simple bilingual termbase at the beginning of the project and then test by adding the simple term ཞི་མི་ = "cat". When I run a parallel test from English to French it works fine:
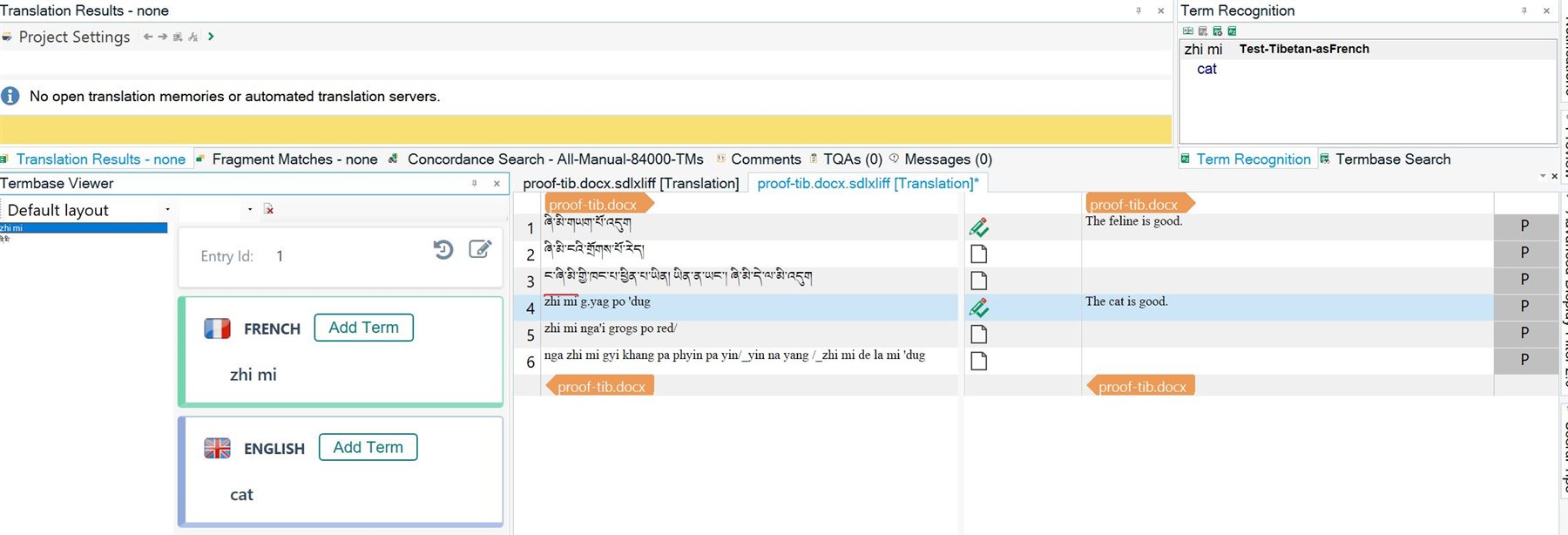
English to French:

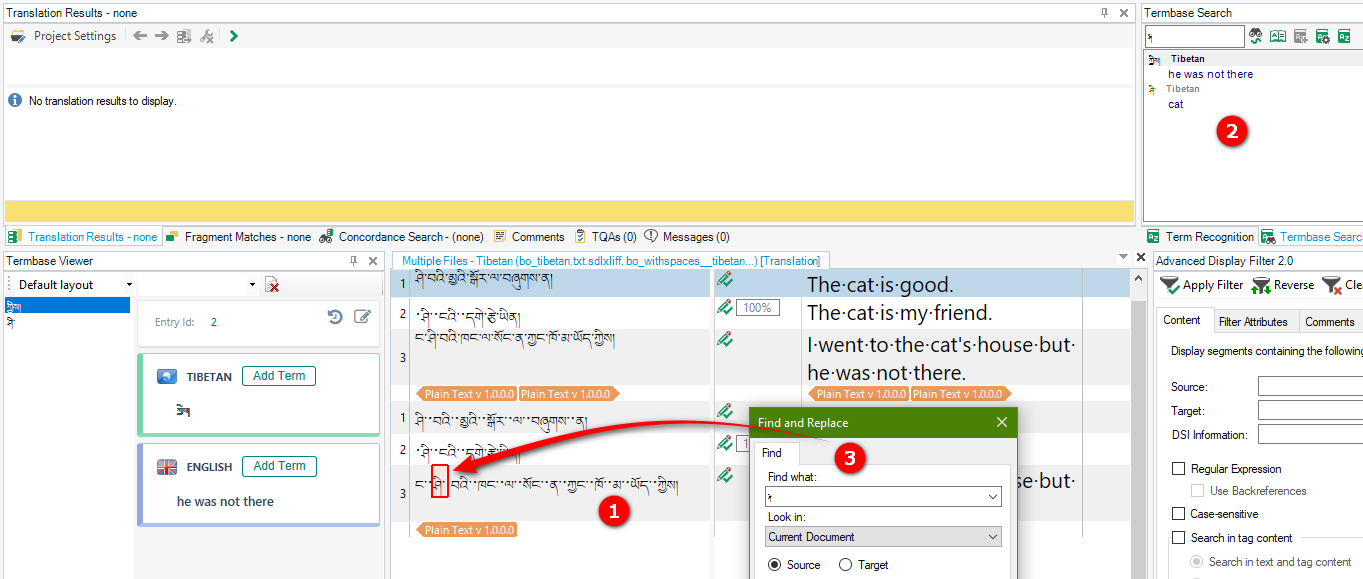
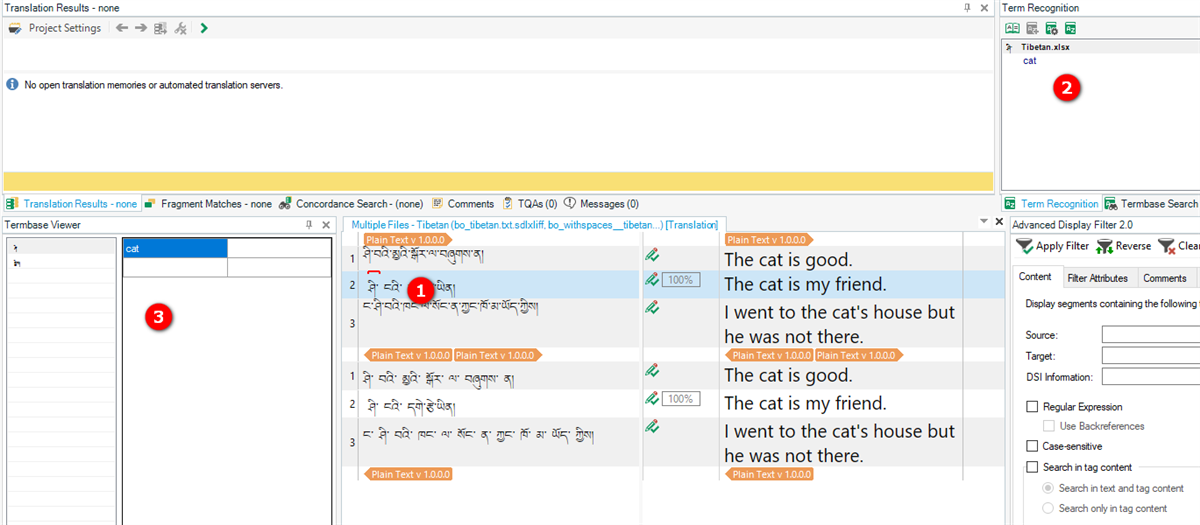
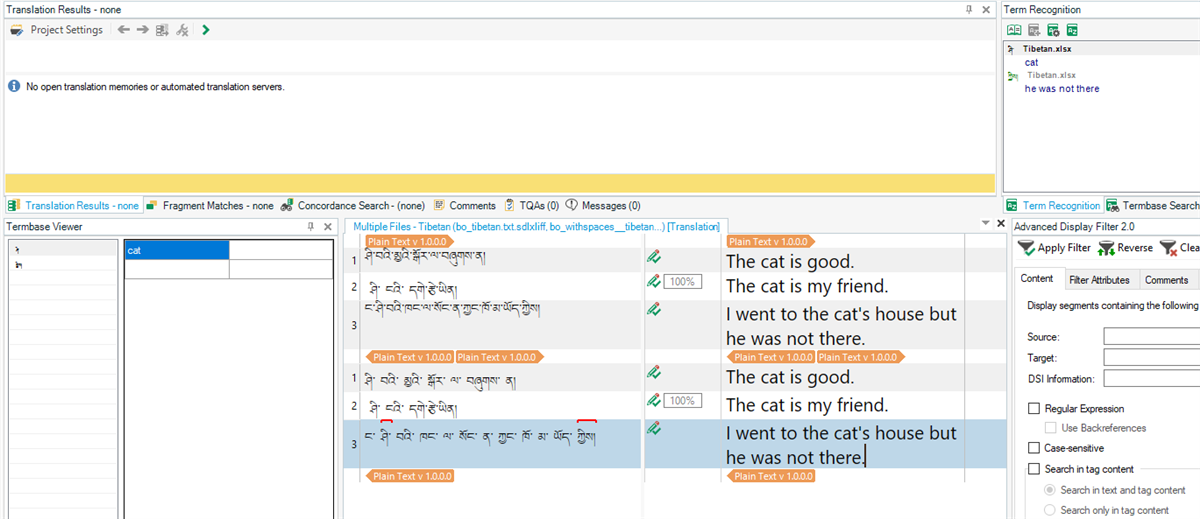
But, no results with Tibetan to English:

I've tried a few different things here. Checking the "Use word-based tokenization for Asian source text" does not seem to help.
I also thought it might be related to the editor not recognizing the Tibetan tsheg punctuation (the little dots between words) as word boundaries--this issue was previously a problem with the TM matching, but was fixed in the 2022 SR1 update. However, as in the example above using roman transliteration with spaces: "zhi mi" = "cat" does not work either.
I know the terms are being added to the termbase because I see them in the termbase viewer and they come up in the termbase search, but they are still not being recognized.
It seems to only occur when the source is Tibetan. Does anyone have some insight into why this isn't working?
Generated Image Alt-Text
[edited by: Trados AI at 2:21 PM (GMT 0) on 5 Mar 2024]