Dear Paul!
Instead of reopening the Term recognition in Trados 2024 thread, which was a bit long, I have decided to start a new one on this topic. Also, after reading your "When close enough...isn´t" article and some testing of Trados and Multiterm 2024 updated to 18.0.2.3255 and 18.0.2.3266 respectively (following your indications).
As I wrote in the previous post, I was positively surprised to see a fuzzy match SUDDENLY retrieved from a Terminology data base, because I have always seen the Multiterm recognition process as a straightforward one, i.e. offering only 100% matches and making the recognition of terms variations in languages with cases impossible (even plural forms made it impossible!). So I was absolutely gleeful at first. According to you, Paul, I have already had it in Trados 2022, and I suspect it appeared in one of theintermediate updates cause I have never updated my Trados 2022 until I got the 2024 version installed. Definetely, version 2021 does not offer this function (tested on my colleague´s PC).
So when a fuzzy match "occured" last week, I spotted it immediately and I am grateful for all the detailed explanations in you Multifarious post on how the matches are calculated (enough for general understanding of a user like me). BUT, my Trados 2024 is failing again. As a well-trained follower of yours, I have prepared an example:
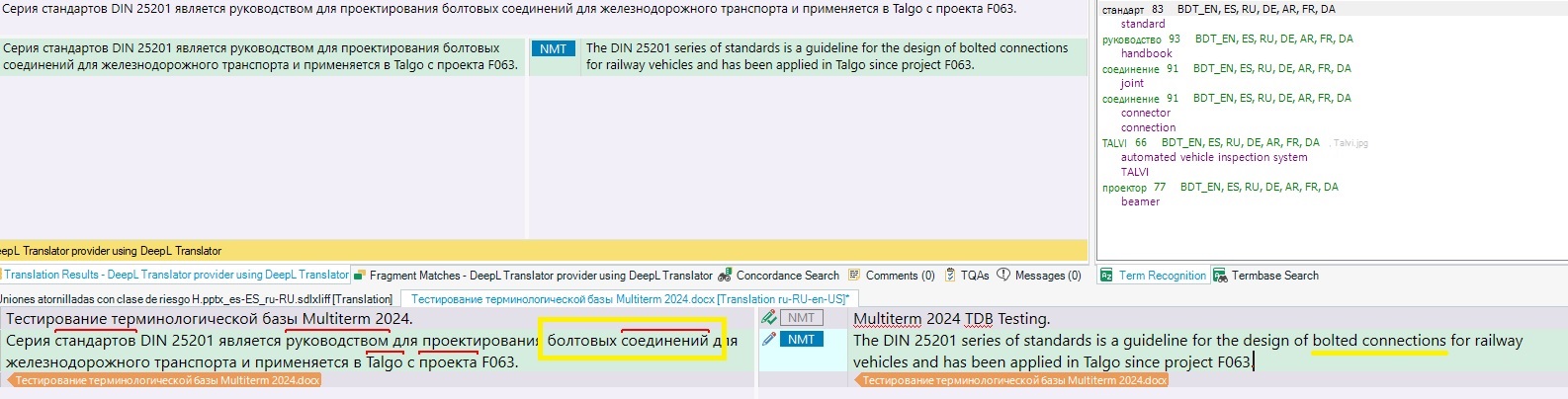
Now have a look at my Multiterm entry:
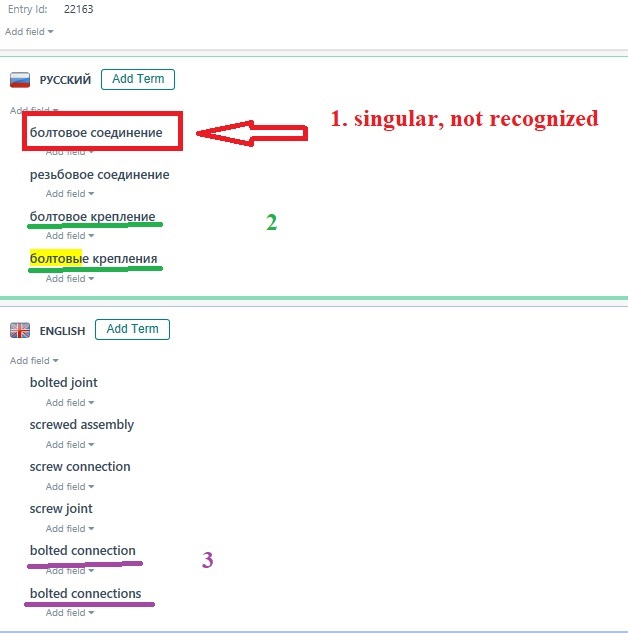
So, the term (example 1) which appears in the text is different from the one saved iun the database (plural and Genitive case vs Nominative case singular), but there are no intervening words, no word order change, only a 4-character difference! And, nonetheless, it is not seen by the Multiterm term engine. The matching value is lowered to 50%, something I will never use actually, maybe 60% , but not 50%.
Example 2 and 3 showcase the non-retrieval of different word forms from the TDB during translation, this is why at some point I recorded their plural forms there.
The first thing I thought about when I came across that fuzzy match in Multiterm, is that I could start deleting all those word forms from the database and that so many words would be automatically detected without the need for their manual fuzzy search.... But somehow it does not work. Any idea on what can be wrong?
Another example:
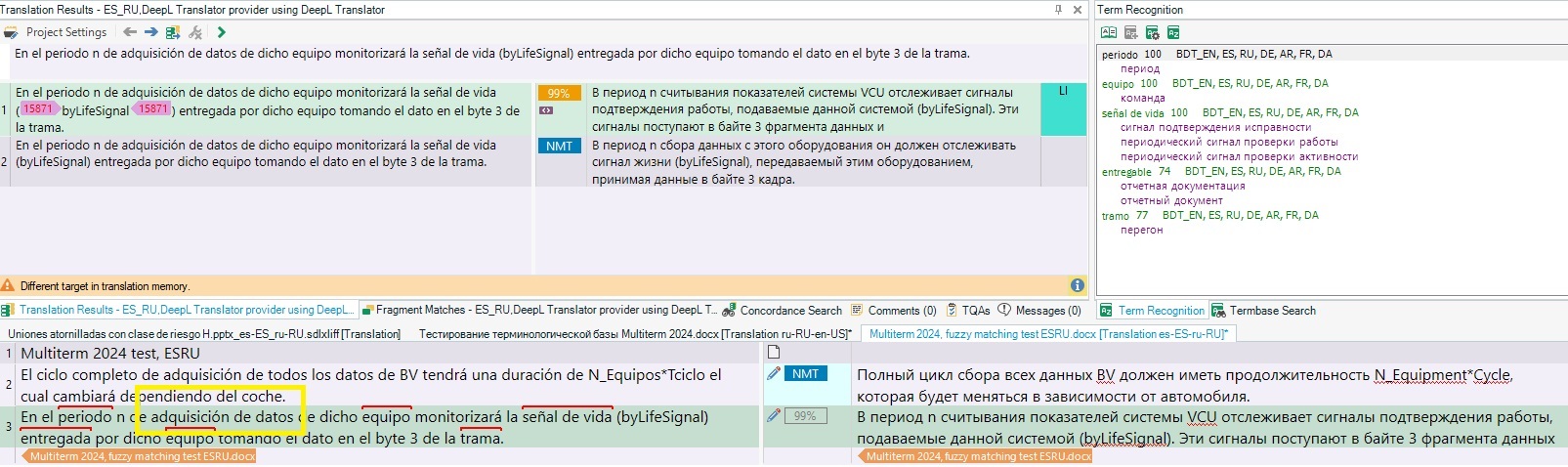
And the Multiterm entry:
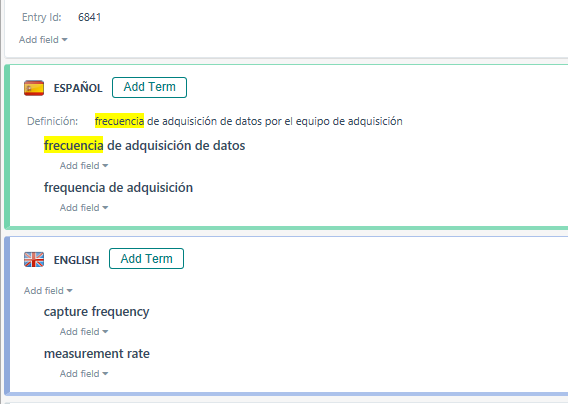
The matching rate set is 50%, however, "de adquisición de datos" is not found :(....
Other resources: Translation memories are great, but what I personally adore about (!!) Multiterm and Autosuggest dictionaries is that they provide lots of suggestions while typing. So NMT+DeepL (correction) glossary+ Autosuggest+Multiterm is a great combo, that could be boosted by the Multiterm fuzzy seacrh....but it just doesn´t work in my case ![]() ... Or works randomly...
... Or works randomly...
BTW! You didn´t mention Autosuggest dictionaries in your article, Paul! Another tool often underestimated by translators. If the memories are kept clean and tidy, Autosuggest dictionaries give wow-results (you know how these are calculated backstage, I only know that it is done really accurately!) . I always generate a new one, based on the latest TM-version, but, for example, my colleagues never do it. Yes, it´s a "static" resource, but its generation takes 5 minutes at most and the benefits are worth these 5 minutes, from my point of view....
MY BOTTOM LINE: fully agree with your opinion, Paul. The change in the Translation industry is non-negotiable. And static TM are ok, but cannot compete with AT. Translators do not "translate" anymore, they review and edit the AT drafts...And this is where, unexpectedly, other resources emerge to help us: terminology databases and AT correction glossaries.
Oh! And there is another tool: termonology-aware automatic translation... still, could not test it ...
So, this was my humble end-user opinion:). If you have any idea on why my Multiterm fails to fuzzy-match, please, share :)...
Generated Image Alt-Text
[edited by: RWS Community AI at 11:57 AM (GMT 1) on 10 Apr 2025]