Hi, I would like to segment the translation memory so that it never breaks at any abbreviation but breaks at the end of each sentence. Here the file is in Excel format, where some cells contain multiple sentences and most cells have no ending period. (This is not an omission: this text represents in-house labels which should not end with a period but which often contain abbreviations which should not be broken.) Taken individually, each rule works fine in a regex tester (.net flavor) but when used for segmenting the TM, they don't produce the expected result. It seems that the rules don't interact properly. Could you explain how the segmentation works? Is there a priority in the application of the rules? Is the parser of the type Posix? NDA? DFA? Also, I would need to know: if <BR> and <br> are already tagged in the file (as inline tags in embedded content), do they 'disappear' in the eye of the regex? If not, how should these tags be represented in the regex literal? Finally, before answering, please note: Our files are most of the time in Excel format, but we also process pdf and doc occasionally. Note as well that an abbreviation list would not be a solution since the abbreviations we are dealing with are not conventional and are numerous.
Here is the sample text (from Excel), and the regexes used in the Language resource segmentation.
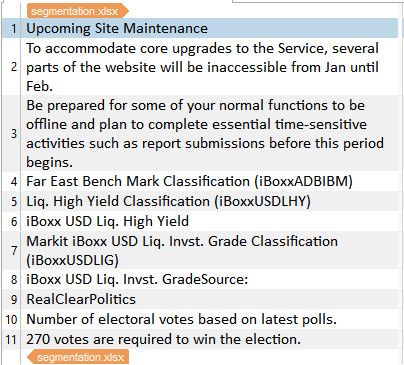
# Upcoming Site Maintenance {0} #\n\nTo accommodate core upgrades to the Service, several parts of the website will be inaccessible from Jan until Feb.<br>Be prepared for some of your normal functions to be offline and plan to complete essential time-sensitive activities such as report submissions before this period begins.
Far East Bench Mark Classification (iBoxxADBIBM)
Liq. High Yield Classification (iBoxxUSDLHY)
iBoxx USD Liq. High Yield
Markit iBoxx USD Liq. Invst. Grade Classification (iBoxxUSDLIG)
iBoxx USD Liq. Invst. GradeSource: RealClearPolitics
Number of electoral votes based on latest polls.<BR>270 votes are required to win the election.
Segmentation goes as follows:
|
|
Before break |
After break |
|
Full stop |
\w\. |
$|\r|[ ] |
|
Lower case exception |
\w+\.+ |
[ ][a-z] |
|
1st abbreviation exception |
\w+\.+ |
\.(([ ][A-Z]\w+\.?)([ ][A-Z]\w+\.?)+) |
|
2nd abbreviation |
(?<=\.[ ]\w+)\. |
([ ]+[A-Z]\w+\.?)+ |
Thanks a lot for your attention.