I'm trying to create a custom XML file type to extract part of an XML attribute value. To make things a bit more complicated, the attribute value is actually an XPath too.
Suppose this XML file:
----
<root>
<Attribute XPath="//Buttons[@Display='Name']" />
</root>
----
I want to translate only Name.
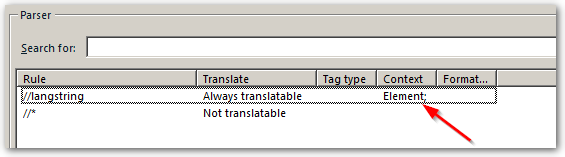
It's easy enough to extract the entire attribute value. Just add //Attribute/@XPath to the parser, and the editor will show //Buttons[@Display='Name'].
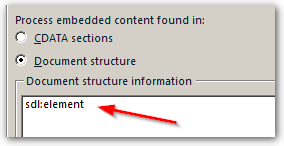
I was trying to get rid of the irrelevant section by means of the embedded content processor:
* Document structure information: Tag (x-tm-tag)
* Tag definition rules
** Start Tag Expression: \/\/Buttons\[@Display='
** End Tag Expression: '\]
However, I still get the entire attribute value. I can't get the embedded content processor to work... I also tried easier tag definition rules, but it doesn't kick in.
Or am I on the wrong track and should I try thing with a more advanced parser rule?
Any advice would be greatly appreciated!