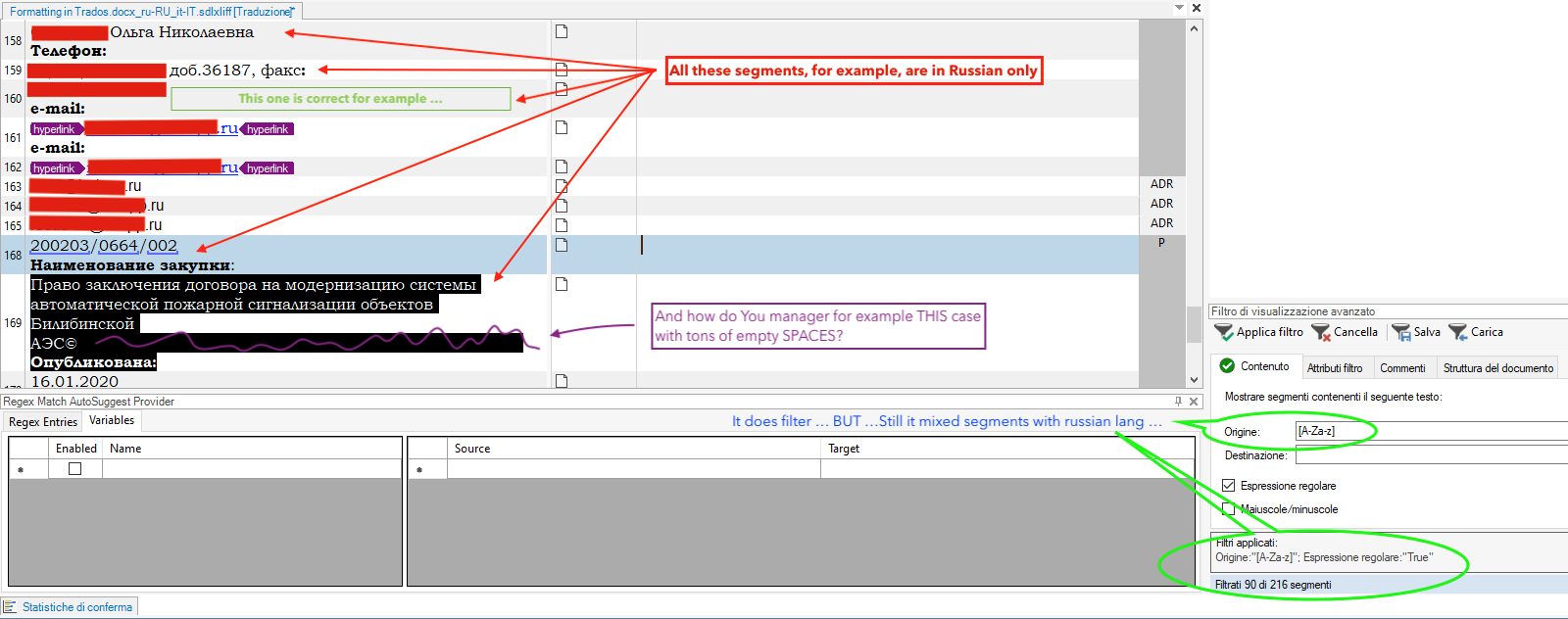
Hello guys ...
I am just starting using a bit of reg ext to find strings with digits (^\d), urls (^\www), telephones etc BUT ...
I translate basically form Russian into Italian and quite often it happens to find in russian source files segments NOT in russian. It happens for instance with brands, company etc ... let's say ... I have in russian files a long list of brancs like like "Ferrari" "Lamgborghini", "AlfaRomeo" ETC ...
My question is, is there a way to build a RegEx which allows me to find segments writte NOT in russian ???
If I have for example this list ... in cirillic and latin alfphabet:
КОМПАНИЯ 1
FERRARI
КОМПАНИЯ 2
LAMBORGHINI
ALENIA SPAZIO
КОМПАНИЯ 3
Is there any way to EXTRACT from that source document ALL the segments like "Ferrari", "Lamborghini" and "Alenia spazio" in order to simply COPY them from source to target and only AFTER THAT start the translation of the REAL russian source ???
Sorry if it sounds strange!
MANY THANKS!
Pietro