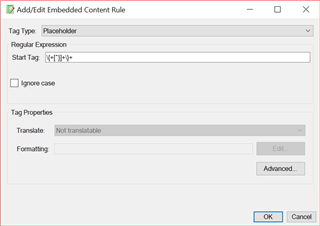
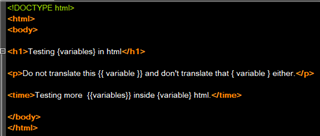
I'm trying to define text enclosed in single or double curly brackets in an HTML file as placeholders. For example.
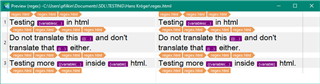
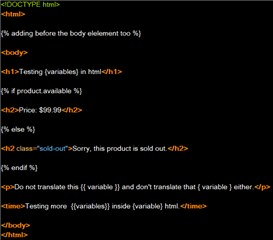
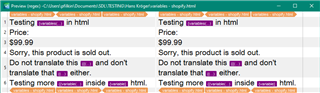
<p>Do not translate this {{ variable }} and don't translate that { variable } either.</p>
The following expression works fine Notepad++, but it doesn't work in SDL Studio.
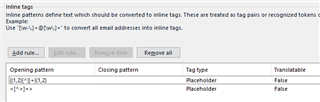
\{+[^}]+\}+
1. Why doesn't the expression work?
1. What regex flavor(s) does SDL Studio support?