Hello,
I am trying to figure out how to exclude part of text using Xpath.
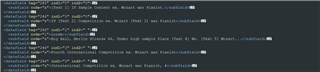
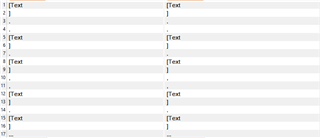
I have sample text in specific structure:
<main>
<section tag="1">
<sub-section id="a">sample_content<sub-section>
<sub-section id="b">sample_content<sub-section>
</section>
<section tag="2">
<sub-section id="c">sample_content<sub-section>
<sub-section id="d">[value_text] sample content<sub-section>
</section>
</main>
I've tried to get text using Xpath:
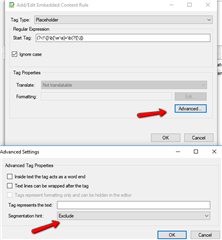
- //section[@tag='2']/sub-section[@id='d]
However, it is not enough to exclude "sample_content" from this line.
Result is:
[value_text] sample content.
My goal is:
value_text
I was looking for solution on internet (this website too) but I didn't get any.
I know that Trados Studio only use Xpath 1.0 that doesn't allow to mix Xpath with regular expressions. Also, I couldn't find any useful Xpath functions for my problem.
Do you have any ideas how to handle this problem?
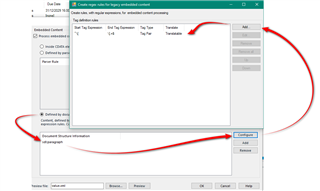
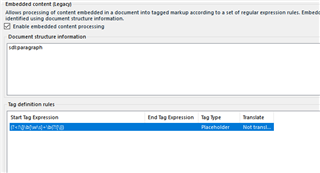
I use Trados Studio 2019 SR2. I created Filetype XML (embedded content).
Kind Regards,
Adrian