HI there
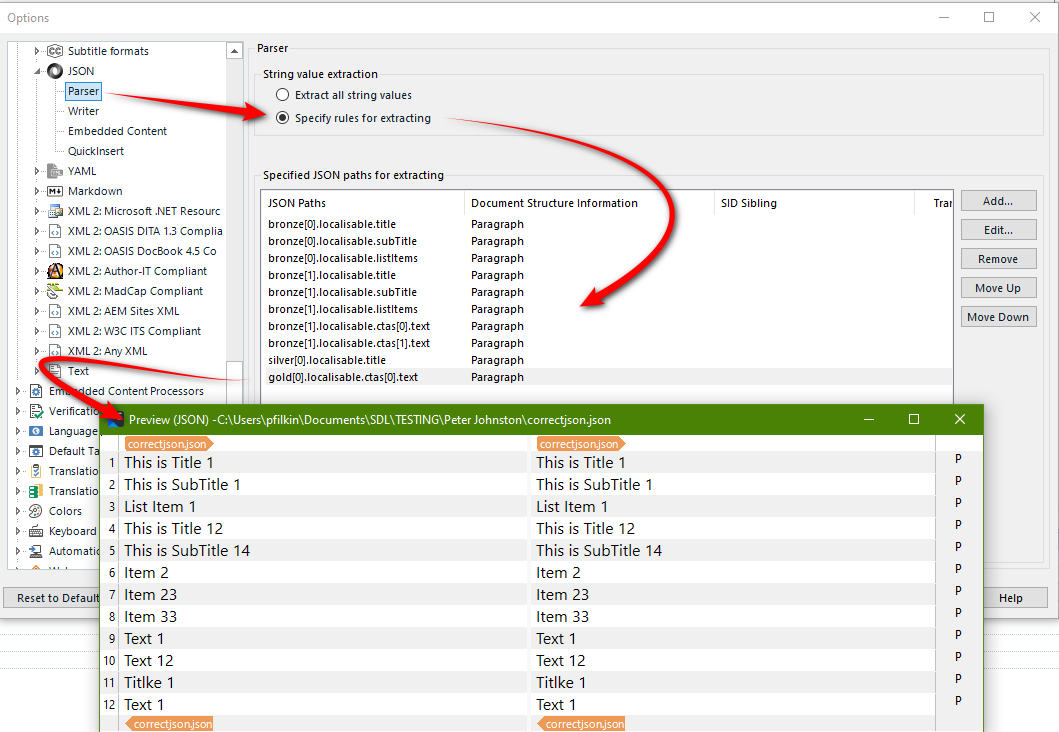
I need to write a custom JSON filetype filter (TRADOS 2021) and am struggling with getting any regex to work for the JSON Paths in Trados Studio.
A sample of the JSON paths that would need to be translated are
bronze[0].localisable.title
bronze[0].localisable.subTitle
bronze[0].localisable.listItems
bronze[1].localisable.title
bronze[1].localisable.subTitle
bronze[1].localisable.listItems
bronze[1].localisable.ctas[0].text
bronze[1].localisable.ctas[1].text
silver[0].localisable.title
gold[0].localisable.ctas[0].text
I can't get the correct regex identified for the words bronze/gold/silver or the digits inside the [].
Any pointers would be appreciated
TIA
Peter