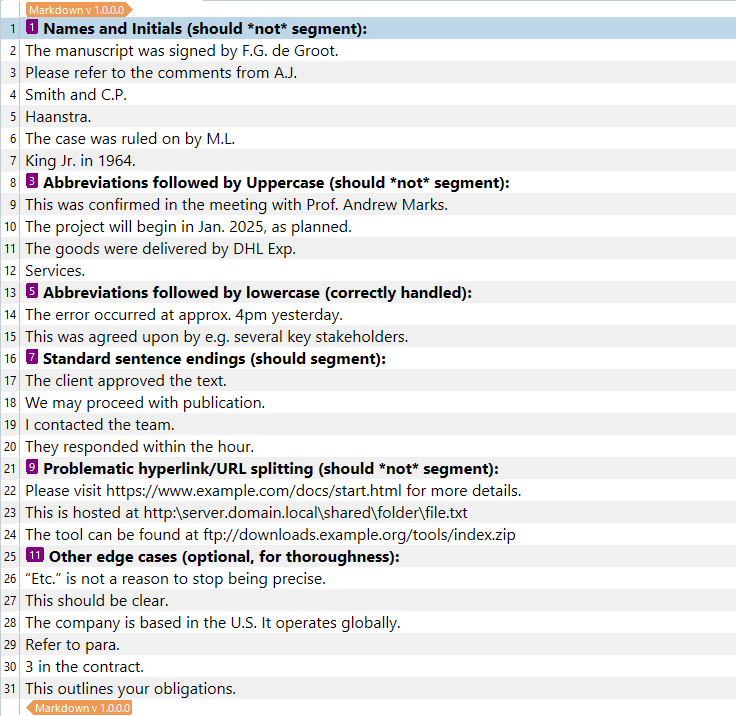
Hi all,
Does anyone know if it is possible to make sure segments are not separated by a full stop in any case that is not the end of a sentence? So for example in names for people, like 'F.G. de Groot', but also after a common abbreviation that is followed by an uppercase in the following word. I've noticed that it doesn't separate the segments when it's followed by a word starting with a lowercase letter. I've also noticed Trados Studio 2022 sometimes breaks up hyperlinks after the :\\, which will have to manually be merged again.
I hope you know what I'm trying to get at and have some solutions for me I haven't tried yet. I've tried \p{Lu} before the break as an exception to the full stop rule (as found under another post in this forum), which seems to work for the names for people (thank god), but that's only part of the problem it appears. And I'm not exactly an expert on what every bit of a regular expression means exactly, so I'm not sure what I need to add or delete in order to get exactly what I'm trying to achieve from it.
Thanks in advance,
Charley