Hello all,
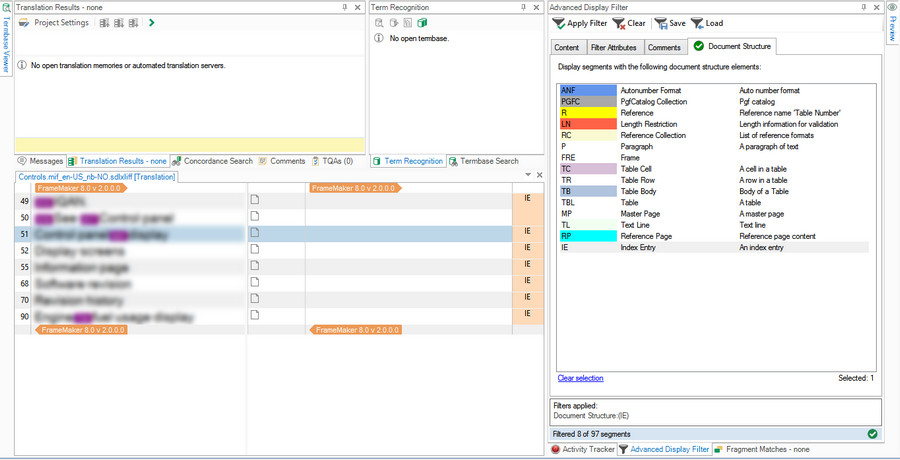
I'm processing a Framemaker manual with an index and tokens throughout the body copy linking back to the index. We've worked with a similar manual in the past, and had each of the tokens in the body copy translated and then had to manually verify that each was translated consistently so that we would not get any added duplicate entries in the target index once re-generated. This added time to our review stage to manually check each of the tokens, and numbers to our word counts.
Are there any filters available in Trados that would allow for index tokens in inline copy to be excluded from the word count? Or extracted? Any other solutions for processing tokens efficiently?
We tried exporting from Framemaker to XML to see if there’s a way we could isolate tokens in the format, but from what I’m hearing from the DTP team, the exported XML file would be something the client would use to publish the content online, and I don’t see any of the tokens displayed in the XML version of the controls file. Sounds like we may not even be able to import that file back into Frame.
Thank you!