In a localisation project we were given reference material which I converted into a TM. We were first given only missing sentences to translate. After translation I created a project TM.
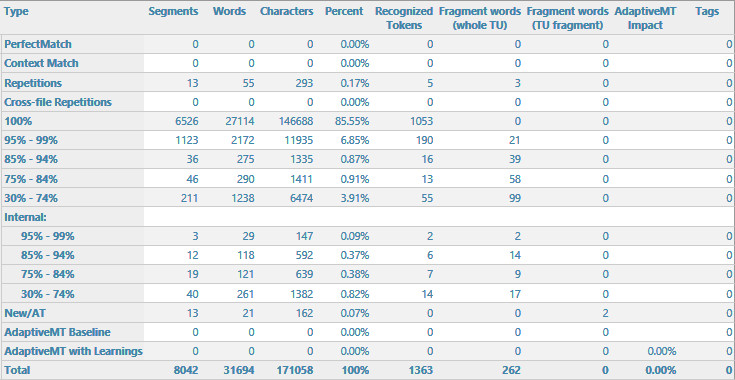
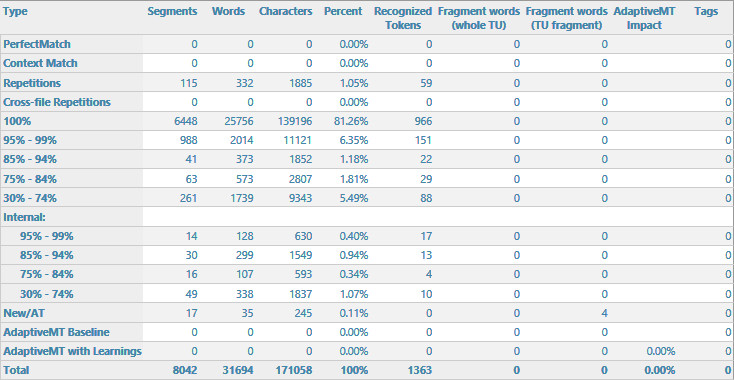
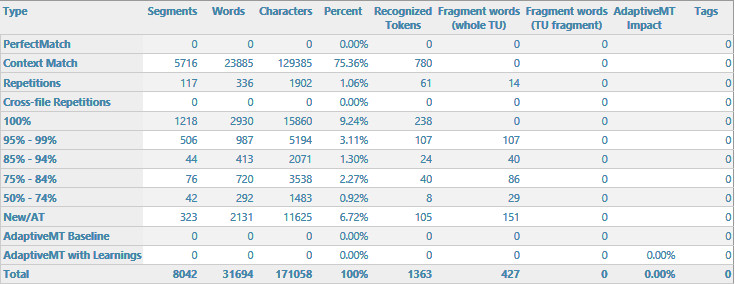
When creating a project with the complete file to localise, only a very small percentage (~0,1 %) was pre-translated.
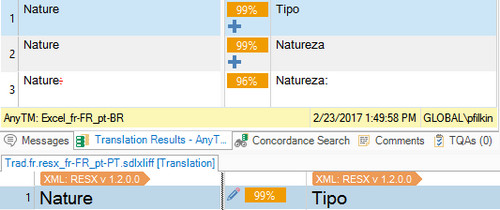
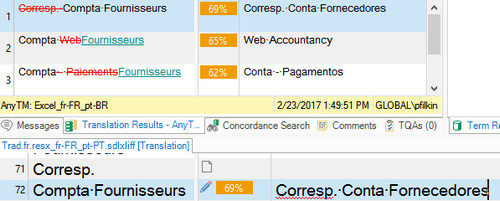
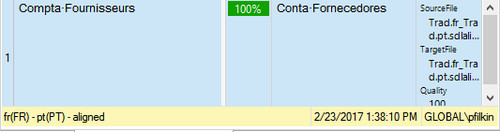
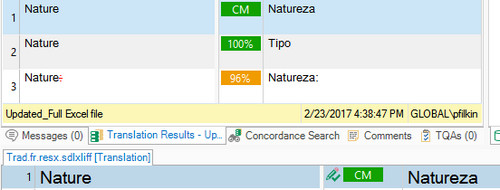
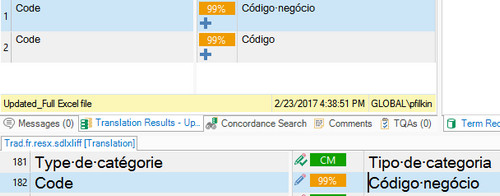
I had checked TM contents previously (they are organised in such a way, that normally we should get only Context matches), and TMs are activated.
What could be wrong?