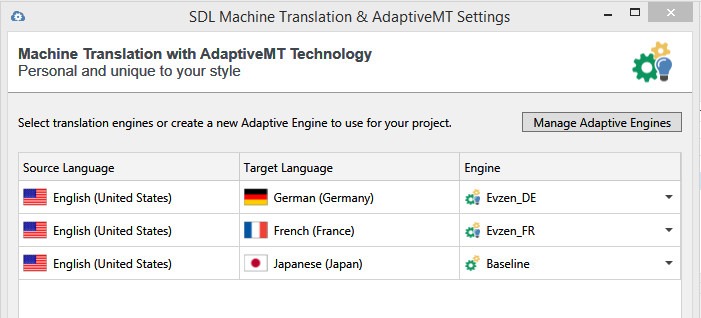
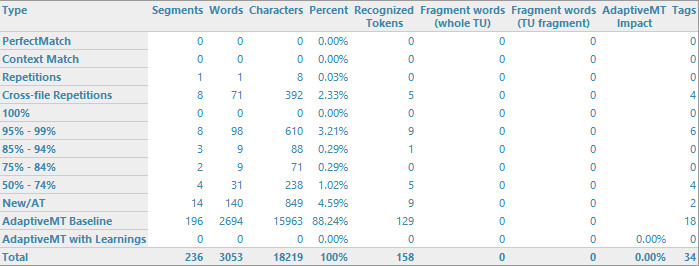
I would need some documentation about how do some 2017 report numbers work in analyses. Read, how do numbers of both "AdaptiveMT Baseline" and "Adaptive MT with Learnings" show up and the process behind. I've tried connecting LC but I see those values again set to zero after my test analysis. As we need to map those numbers to our erp system, I'd like to know how and when they become <> 0 (I assume a simple and informative subset of New/AT? Just like tokens for their reference lines, right?). Is there any specific documentation for that? I've only found what they are basically, but I can't figure out how and the reason behind their change from 0 to something different because this will affect the way the system is picking them up. The xml line I'm referring to is adaptiveWords="0" baselineWords="0". At the end and in a nutshell, I need a way to repro a change of their values.
Best, Matteo Rozzarin
RWS Community