Hi all
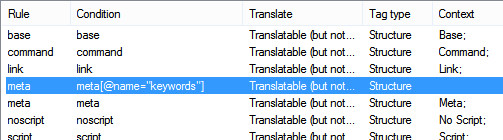
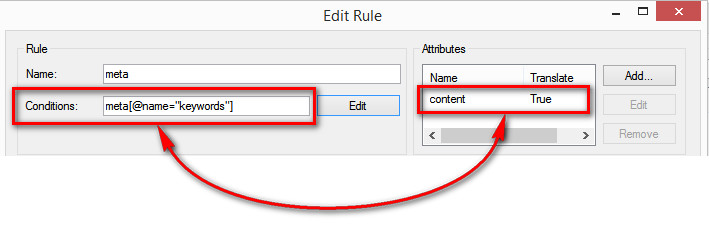
Just double-checking something in relation to meta tags extraction. I've extracted meta content from a webpage in order to translate the relevant keywords and description. I did so by making the attribute translatable as also indicated in other forum posts.
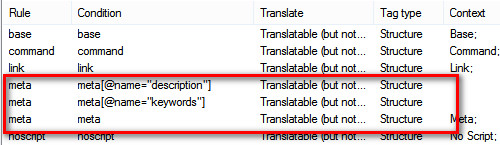
In the Studio Editor, however, I get all other types of content attributes,i.e. meta property, viewport, encoding, etc. (see segments 1 and in yellow below):
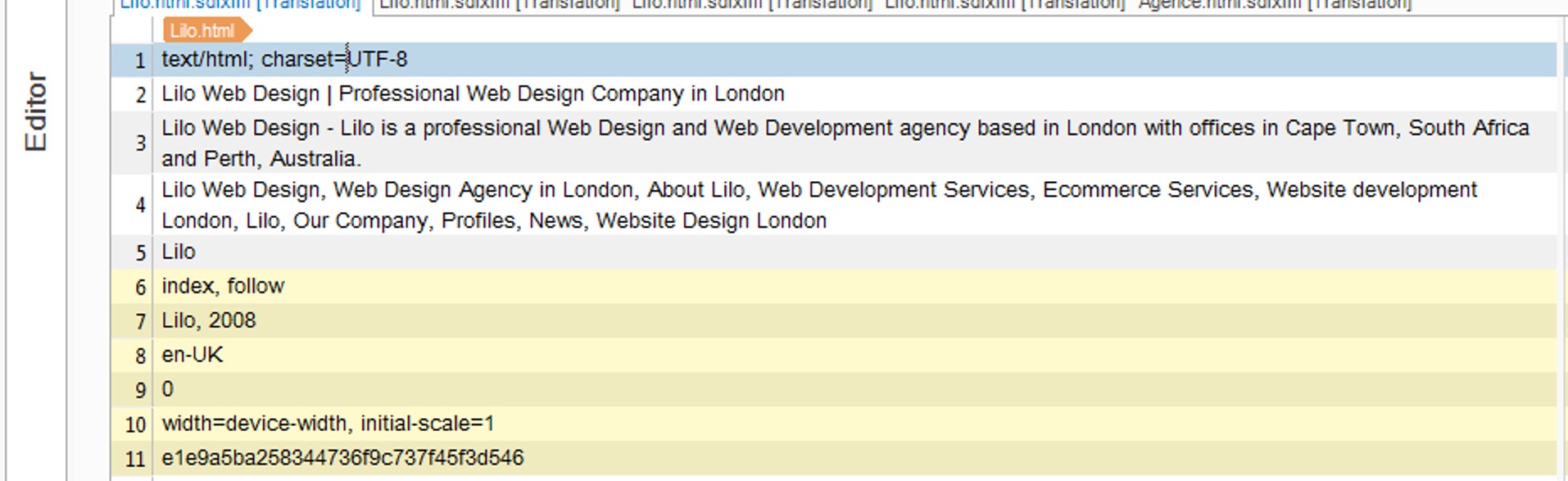
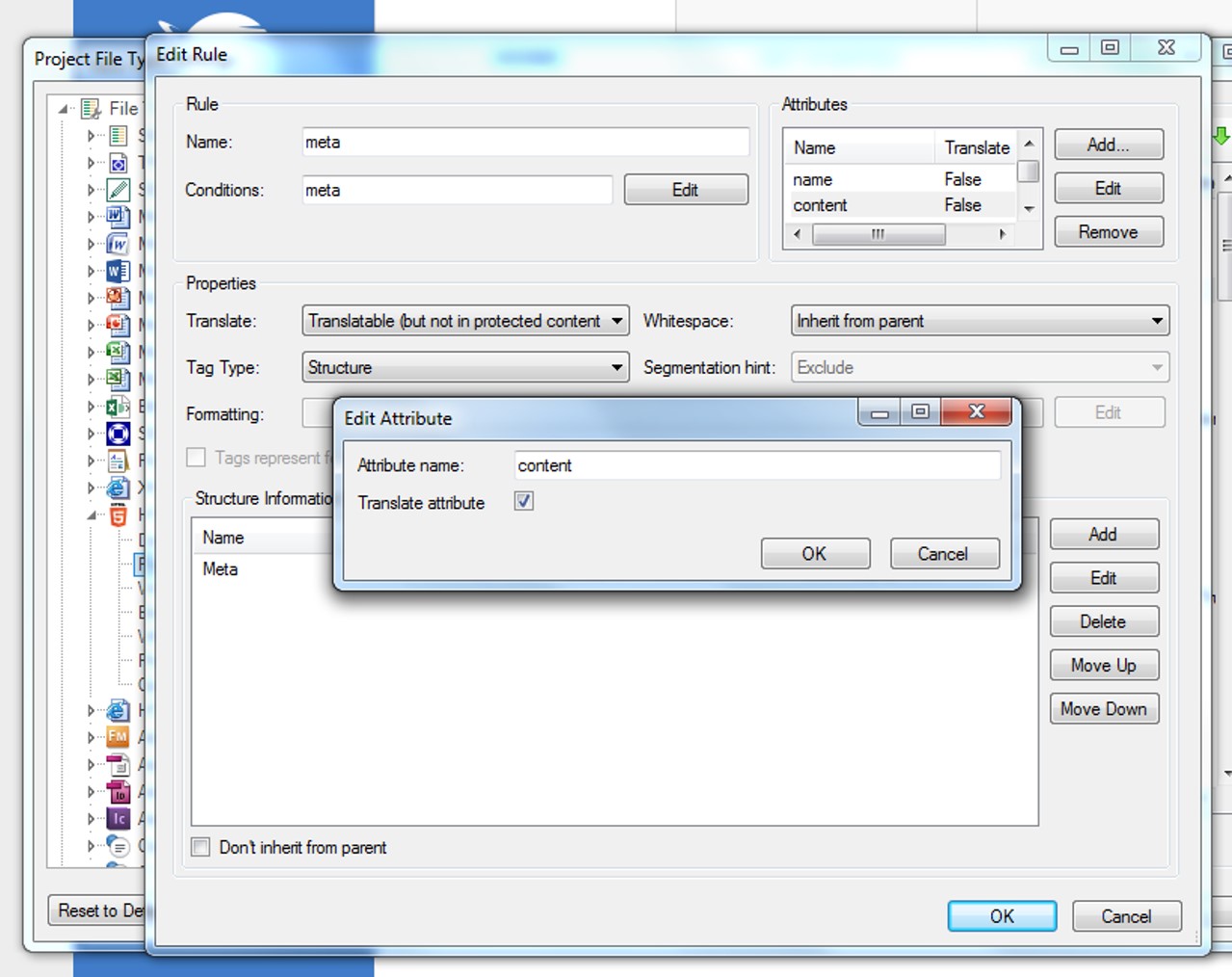
Is there a way to hide them, apart from locking those segments? I saw this presentation by Paul online which recommends using the SDLXLIFF Toolkit, but I was wondering if I could tweak the HTML Parser settings from within Studio? I tried playing around with the Elements Conditions (i.e. editing the Rule) but to no avail:
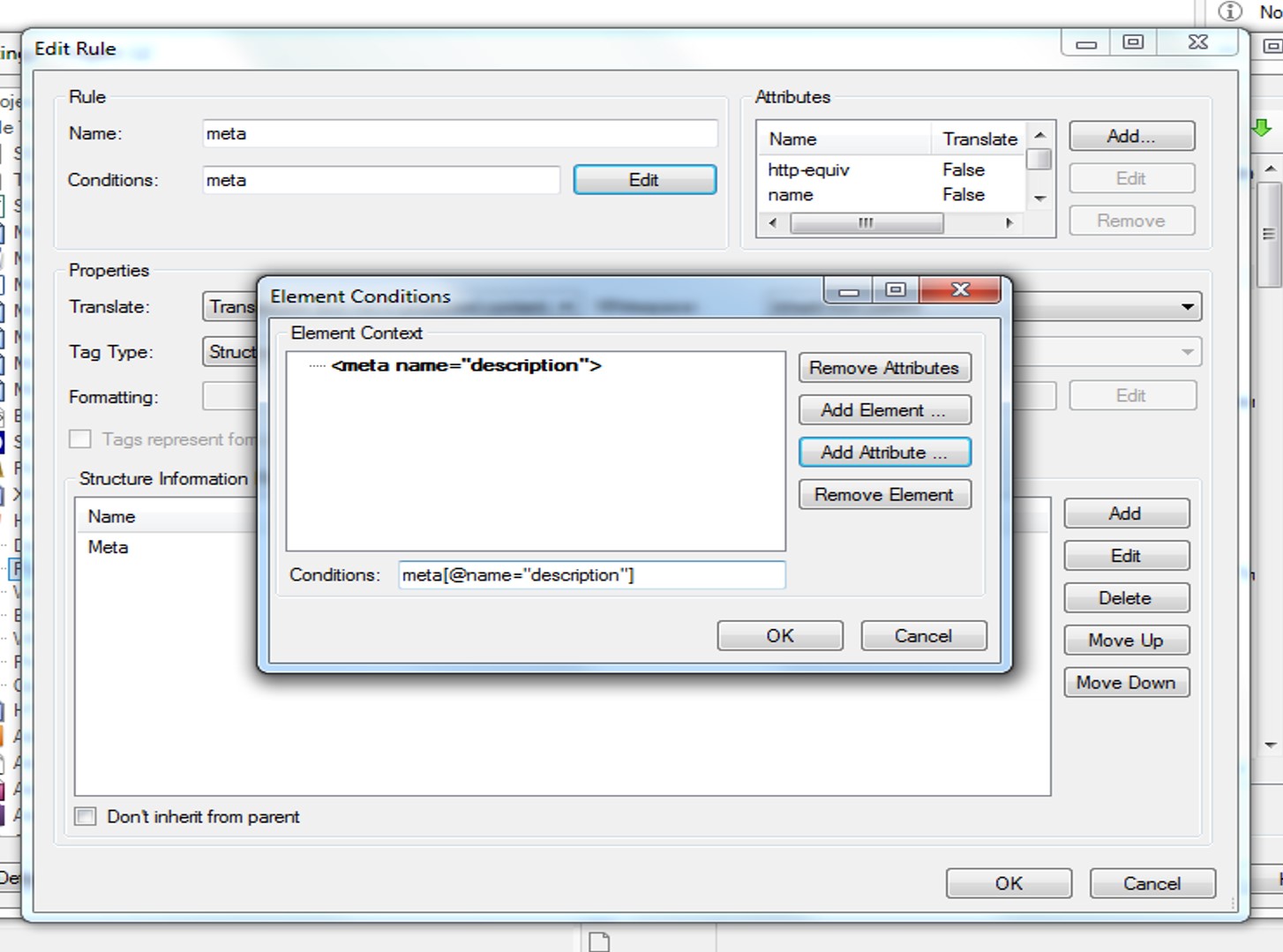
Any suggestions please?
Thanks in advance.
Piero