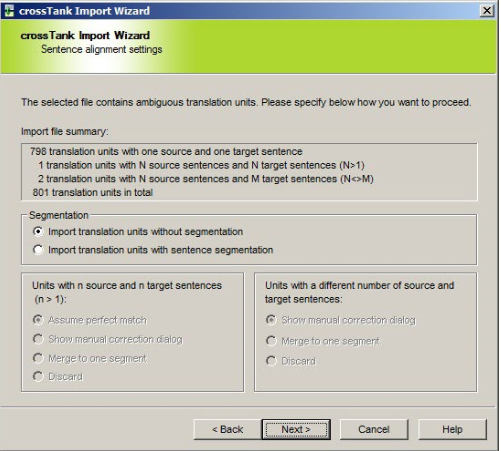
Hi,
I have done an alignment (German/English) via the bilingual excel file type and the complete Excel cells (more than one-sentence, the same happens with bilingual (SDL)XLIFF files) were saved as TM segments in the Studio TM (see attachment). The TM segmentation, however, is set to full stop rule (sentence-based).
I could have copied them into 2 excel files and perform a traditional alignment which would have worked, too, I know. But I wanted to show it using just 1 file. The result – referring to the TM segmentation - strikes me as odd :/. As the (customer-related) data is confidential, I do not post it or any screenshots of it here.
If I import a new excel sheet for translation using the same TM which will then be segmented according to the full stop rule, I can only use upLIFT matching or concordance search, but not fuzzy matching (< 70%).
As far as I know, there is no easy way to re-segment TMs in Studio using the features integrated (e.g. TM maintenance)? Am I right? I also read the following related article that you cannot change segmentation rules for the bilingual excel file type in Studio:
https://community.sdl.com/solutions/language/translationproductivity/f/90/t/8575
I wondered whether you had experience with tools such as Olifant or even a useful script for re-segmenting a Studio TM or exported TMX file? Is there an app for this? I could not find any on the AppStore.
Thanks a lot!
Best regards,
Manuel