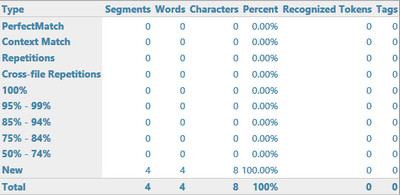
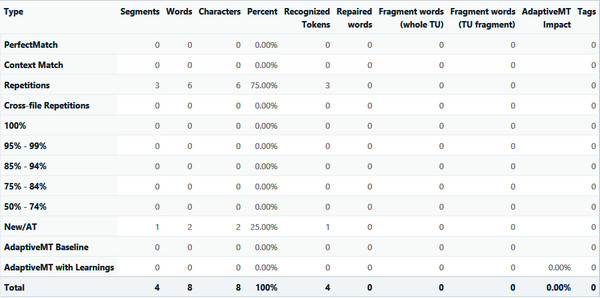
Since switching to 2017 from 2014 we've noticed a different in the Korean word counts. Minor differences are to be expected, especially across major version numbers. However, our Korean team informs us that this particular case was correct back in 2014 and now is not right. We have many situations in our source texts where words such as:
‘제1’ roughly meaning 'first' is counted as 2 words where it should only be one.
This has upped our word counts significantly and our clients have noticed. Is there any way in-interface or behind the scenes to fix this?