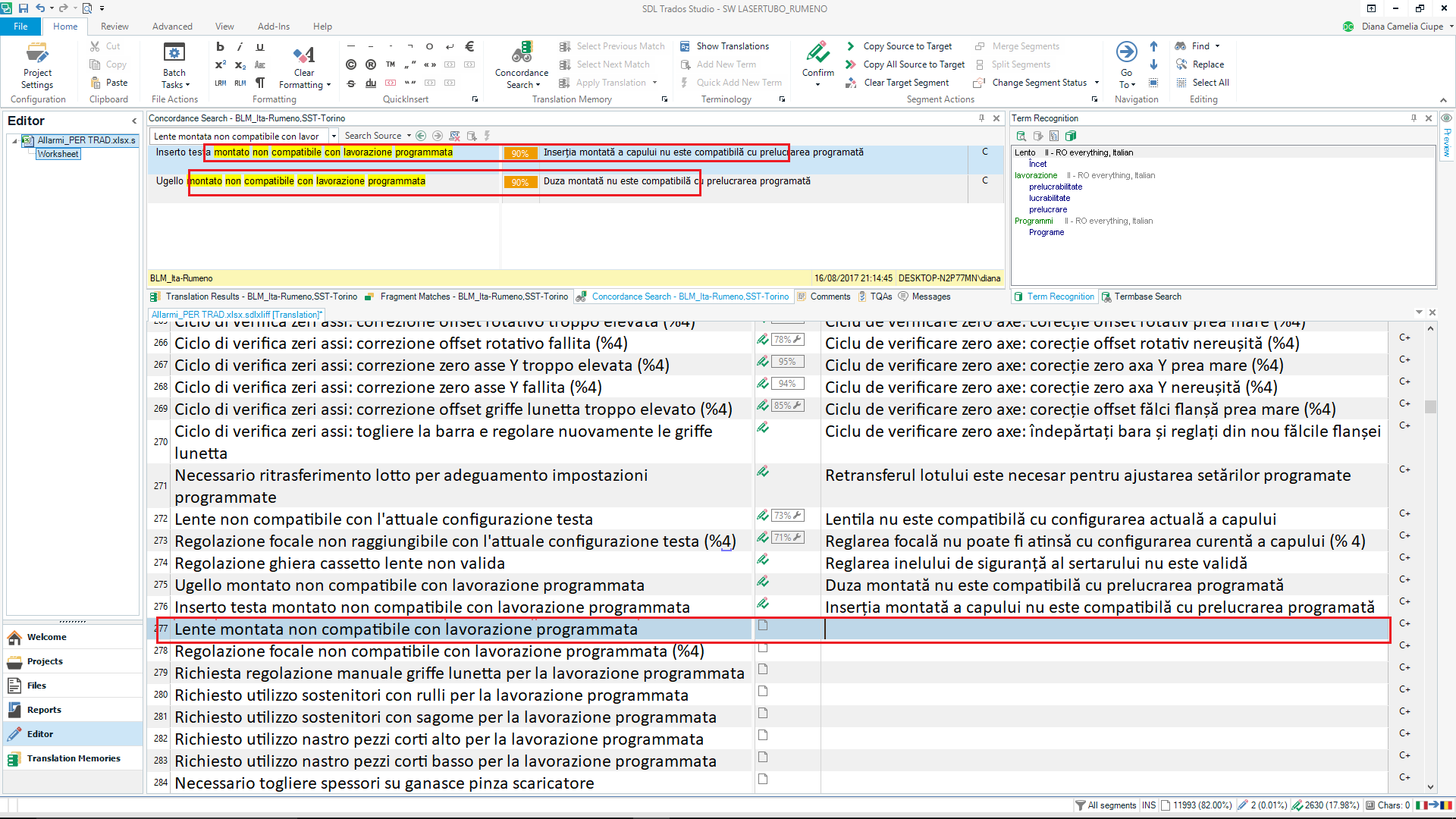
Hi! I am running the latest update of Trados Studio 2017 (SR1 - 14.1.6284.6) (Freelance version) on a Windows 10 platform. Since it installed, most of the fuzzy matches are no longer propagated in Editor - they are no longer recognised in the Translations Results window at the top, although they are shown in the Concordance window. This is quite annoying and it slows down my work a lot.
Furthermore, only random matches are recognised (e.g. a segment with 90% match value is not recognised, while a segment with 76% match value is, but this is does not work as a rule).
I would like to mention that I uploaded the same project into MemoQ 2015, and here the matches work perfectly.
Any piece of advice would be highly appreciated.