

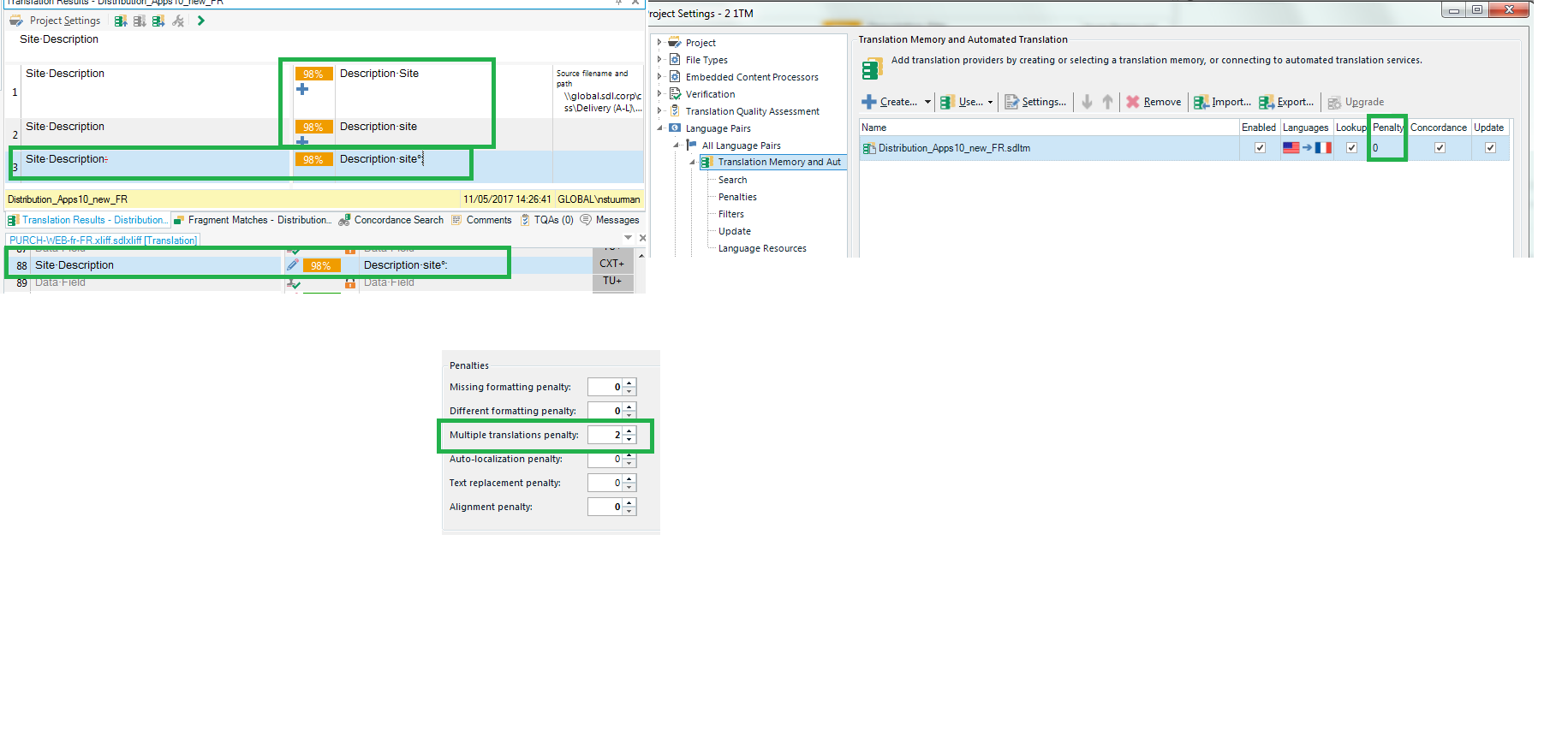
On one of our clients, we have a rather complicated TM strategy, with between 11 and 22 TMs that need to be applied to every project. The Master TM gets applied without any penalty, except the Multiple Translation penalty which is set at 1%. The remaining TMs get applied with a 1% penalty for each TM as a whole plus the 1% Multiple Translation penalty. So far so good, as this works fine.
However, we were recently asked by the client to increate the Multiple Translation penalty to 2%, and at this point things started going weird because items that were a 99% match thanks to the Multiple Translation penalty at 1% suddenly became Context Matches with the Multiple Translation penalty at 2%, while the expectation and requirement was for them to become 98% matches. The increase in the Multiple Translation penalty is the only thing that has changed.
I also tried the analysis while applying only 1 TM, rather than the multiple TMs the client requires, and in this case the affected segments do display as 98% as expected. However, in this case it is not one of the multiple matches that gets applied, but a different match for slightly different source (see screenshot 2%_one_TM). Again, this is not what is expected and required or expected.
has anybody seen this behaviour before, where increasing the penalty percentage changes a fuzzy match into a context match?
We are expecting a project with hundreds of thousands of words into 18 languages at the start of 2018, so it would be good to get this working


{kind=link}