Hello,
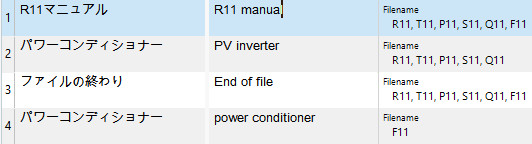
I manage the TMs and translation resources for my company. When I import a TU with a custom set of fields (filename, category, subcategory, translator, date entry, native check) and then import the exact same TU from a different project with a different set of fields, the original TU is overwritten. Instead of having 2 TU's I just have 1. This is problematic. If one TU is used for one manual, then overwritten with info from another manual, the reliability of the TU is put into question even though it could have been used serval times.
Is there any way to stop this from happening? I would like two TU and not like old TUs to be overwritten.
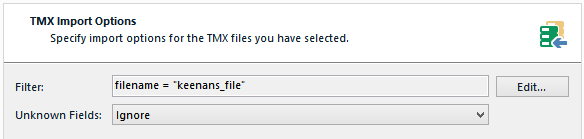
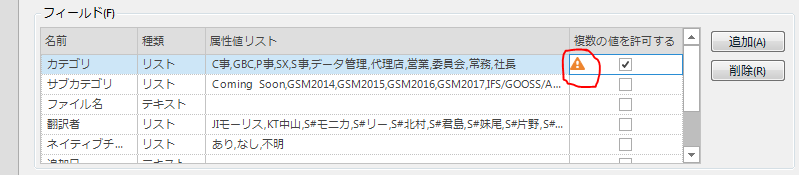
As of now, the only way I know how to NOT override an old TU is to import the new TU into another TM. I split our master TM into 3 TMs for our main divisions and this sorta helped. Another workaround is to customize the field settings of the TU to allow for multiple values. That way I could keep track of where the TU was used (useful for manuals or say makings sure that speech from the president of company stays associated with the president). But this would lead to really huge "filename" fields for me and would potentially take an incredibly long time to initiate because this setting can only be done from a fresh new TM... right? How would I do this for a TM with a few hundred projects and several 10s of thousands of TUs?
So anyway, if anyone has a good translation memory management method or tips, especially for in-house translators, I'd love to hear yr thoughts.
Best regards,
Keenan