


Dear SDL Community,
I'm facing an issue with statistics / analysis.
My client uses MemoQ, I'm a Trados 2007 user.
For new projects, they send me the files and their statistics which is different from what Trados returns upon performing an analysis on the source files.
The client of course deems their statistics to be correct.
Do you possibly have an idea where this discrepancy is rooted and which settings I should change to obtain the same figures as my client?
Here's the client's analysis:
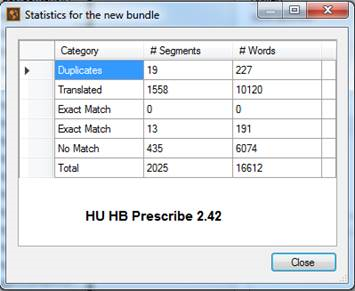
And here's what Trados returns - for the same package of files:
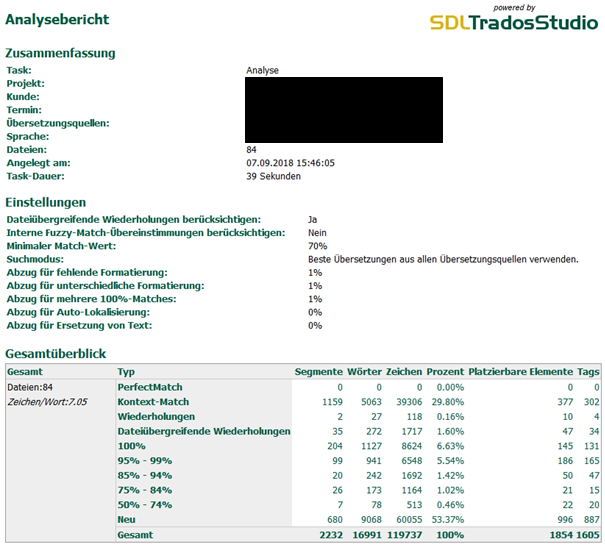
As you will see, not even the number of segments is the same in both analyses.
However, the client would like me to submit my quote based on the analysis.
Any hints on this please-? Your help is much appreciated - thanks very much, best,
Anna
Generated Image Alt-Text
[edited by: Trados AI at 2:14 PM (GMT 0) on 28 Feb 2024]


