I get a lot of keywords lists for translation which are comma separated but without spaces i.e. I get
roses,daffodils,anemones,dandelions,crabgrass,banyans
Studio doesn't like it when there is no space after punctuation (same applies if they use ; instead of , to separate lists) and treats these as ONE word and I end up having to create an intermediate document where I replace , with \n and then do the reverse in the output i.e.
roses,daffodils,anemones,dandelions,crabgrass,banyans
»
roses\ndaffodils\nanemones\ndandelions\ncrabgrass\nbanyans
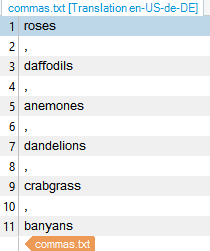
which Studio parses into
roses
\n
daffodils
\n
etc
and then the reverse with the translation. Problem is, these keyword lists are often interspersed with "normal" strings with commas and that gets messy.
Is there a way of getting round this? I had considered parsing but I don't really want to swap every , for \n or something because that will break other sentences. Similarly, if I tell it to (not that I'm sure how I'd "say" that in the segmentation rules) put a space after every comma, then a , space will turn into a , space space which isn't great either.
Is there a better way?