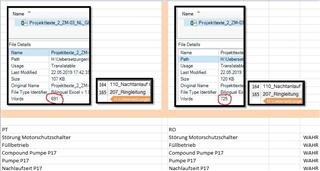
A project was created (in SDL Trados Studio 2017) with three source files being translated into 25 languages. Of these 25, 23 languages have a total word count of 930 words, except for two (Polish and Dutch), which have a total word count of 929.
What could explain this difference?
A new analysis (after completion of project) of the only the affected languages now show 930 words.
Any ideas?
Thanks,
Ines