Hello,
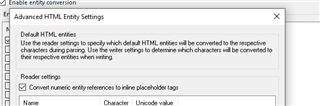
I have some HTML files encoded in utf-8 without a BOM that contains certain symbols Studio 2019 SP1 does not recognize (one is U+10AA16), but instead of showing an invalid character (box symbol), the character is silently stripped from the file.
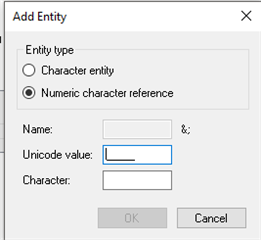
I used the File Encoding Converter to add a BOM but the character was still stripped. I remember reading something about Studio stripping unicode values which are not valid in XML, could this be my problem? What would be the best way of protecting these characters so that the correct unicode value appears in the target file?
Many thanks for any tips,
Daniel