Hi all,
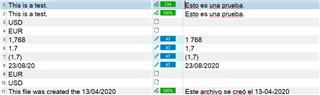
The point here is that when I pre-translate with an empty TM a test file that contains some tokens such us figures, acronyms (three letter currencies) and dates only figures are auto-localized even though the settings are configured to recognize all tokens (including acronyms and dates) in both my TM settings and the auto-substitution settings of the target language pair. Is there a way to also auto-localize the tokens that I have mentioned?
The practical case would be a huge file that has a lot of repetitions. In this case, extracting an Unknown Segments file using an empty TM would be very useful to get rid of all those repetitions. The problem arise when Studio only extracts one of those TUs containing only tokens (such us dates or acronyms) since the rest are treated as repetitions but then, if you try to pre-translate the source file with the translated Unknown Segments file all those tokens are not automatically localized and need manual fixing.
Many thanks in advance to any helpful idea!
Kind regards,
Carlos