


Hey everyone,
I'm struggling to convert character entities in the CDATA section of an XML file. The content is in German, so there are umlauts all over the place...
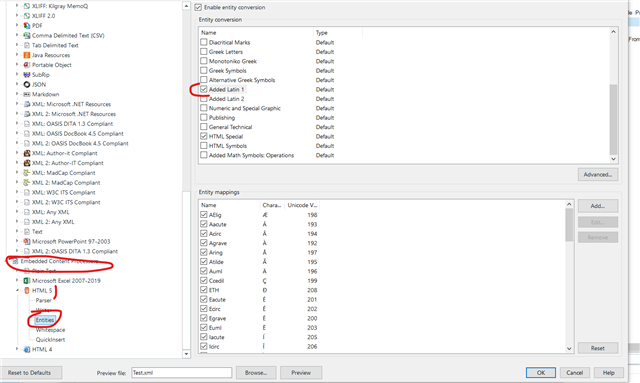
The source file is inconsistent in the way it annotates the entities: sometimes it uses the numerical annotations, sometimes the alphanumerical.
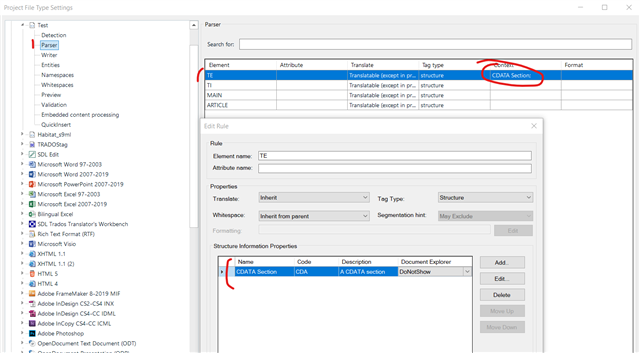
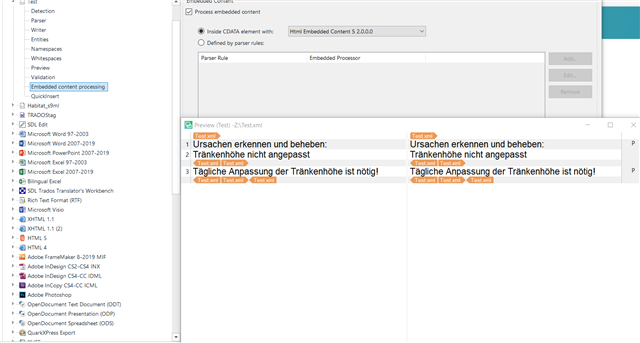
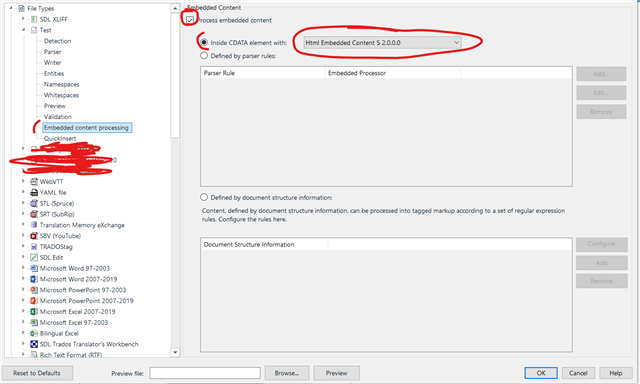
I know character entities are not needed in CDATA elements, but they're there nonetheless...
Here's a sample of the XML file:
<ARTICLE>
<MAIN>
<TI>Ursachen erkennen und beheben: Tränkenhöhe nicht angepasst</TI>
<TE>
<![CDATA[<p><strong>Tägliche Anpassung der Tränkenhöhe ist nötig!</strong></p> ]]>
</TE>
</MAIN>
</ARTICLE>
The entities in the TI element are converted correctly. The ones in the CDATA element are not.
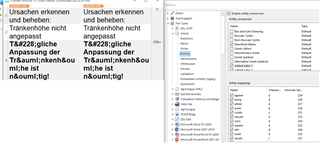
Is there any way Studio can convert them?
Generated Image Alt-Text
[edited by: Trados AI at 10:22 PM (GMT 0) on 28 Feb 2024]







 Felipe
Felipe