


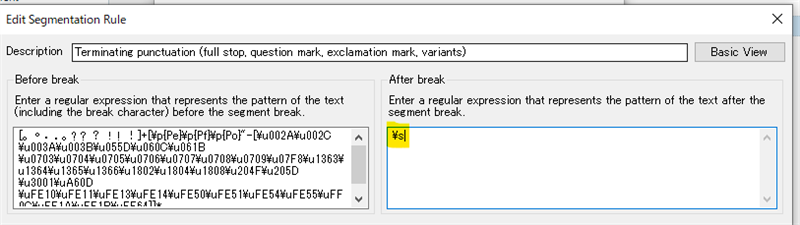
If I look at the segmentation rules on my TM (language pair is Japanese to English), it shows the following segmentation rule.
As you can see, it says a "\s" (whitespace character) is required after the break. However, according to my tests, this whitespace character is ignored and the segmentation happens whether there is a whitespace character or not. Does anyone know why the segmentation rule is ignored for Japanese?
Generated Image Alt-Text
[edited by: Trados AI at 12:16 AM (GMT 0) on 29 Feb 2024]

