Hi Community!
I'm trying to prepare a file for translation and I don't know how to segment it. It contains product descriptions that if segmented properly are quite repetitive. I'm using Studio 2021 Pro, the file type is .xlsx (Microsoft Excel 2007-2019, SpreadsheetML v. 1).
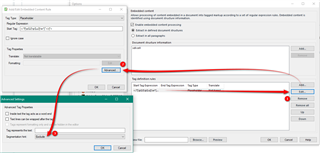
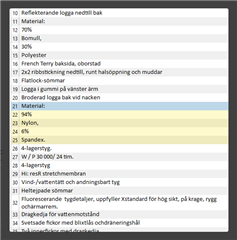
The file is big, but I selected these three cells as an example:
I created a new empty TM using default settings (I didn't change segmentation rules) and in Project Settings I ticked "Enable embedded content processing" under File types - Microsoft Excel 2007-2019 - Embedded content. I didn't make any other changes.
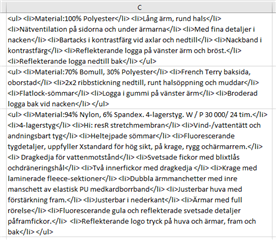
And here are the same cells in Studio:

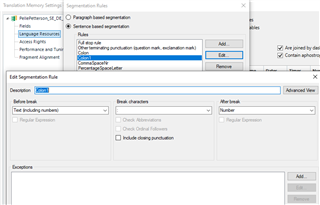
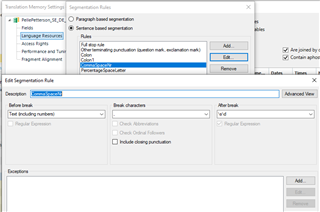
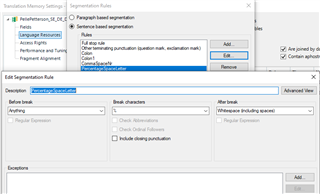
Is it possible to split these segments between the tags, so that each segment has its own opening and closing tag? For example, if I can have this as one segment:

Or is it also possible to segment the file in a way that the segments only contain text and not the tags? Like this:

The target file needs to contain the same tags/code that are in the source file, so I can't just remove them from the Excel file.
Another option that I could think of is to untick "Embedded content processing" and try to write a regex to separate the code from the text. I don't know if that is feasible nor how to write that regex, though.
I'm not sure if I think in the right direction(s), so any suggestion about how to prepare this file is more than welcome. :)
Thanks!
Milena
Generated Image Alt-Text
[edited by: Trados AI at 12:10 AM (GMT 0) on 29 Feb 2024]