Hi,
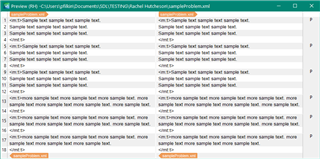
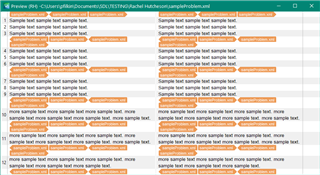
I regularly have to translate files which have been imported from another translation software and feature strings of random characters within segments, e.g. </mt:t><mt:p/><mt:b><mt:t>.
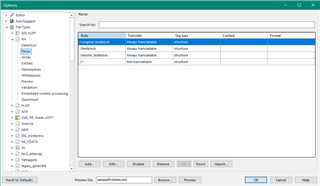
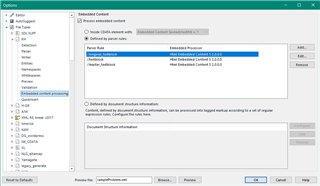
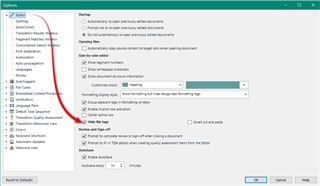
I want to make it so that Trados automatically starts a new segment after these characters but cannot figure out how to do it. I think that they represent the presence of bullet points in the original software but this has not transferred well into Trados. I cannot delete them because I need to be able to transfer the translation back into the original software at the end.
Is anyone able to tell me how to make Trados automatically start a new segment after these characters? It would make my life so much easier if someone was able to show me how and I would be eternally grateful! The files are imported as .xml.sdlxliff files.
Thank you in advance.