I've got an XML structure with nodes like this one:
<p id="260">This document covers the <Model>.</p>
I want the content of the <p> nodes to be translated, except for <Model>.
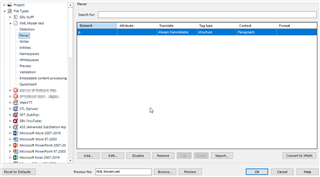
I've set up an XML (Legacy Embedded Content) file type. In the Parser rules, <p> is set as translatable.
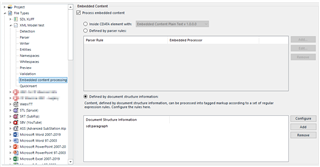
In Embedded Content (Legacy), I've set:
- checked Enable embedded content processing
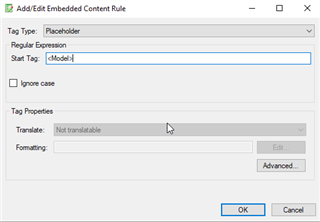
- Document structure information: added a custom type named "Variable"
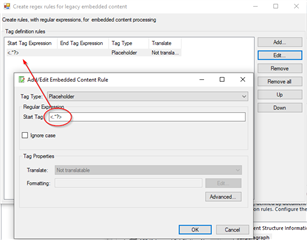
- tag definition rules: start tag> end tag < Tag pair, Not translatable.
Now in my preview, I expect a segment "This document covers the "
Instead, I get "This document covers the <Model>."
So my embedded content isn't being filtered out. I'm doing something wrong, but what?
<?xml version="1.0" encoding="UTF-8" ?> <?xml-stylesheet type="text/xsl" href="AuthorIT.xslt"?> <AuthorIT version="20.3.1.40442" xmlns="http://www.authorit.com/xml/authorit" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.authorit.com/xml/authorit AuthorIT.xsd"> <Objects> <Book wordcount="25"> <Object> <Description>Headers and Footers</Description> <GUID>9e6905caaefa4b019204e85a0bd8789e</GUID> <ID>6116</ID> <VariantParentID>4091</VariantParentID> </Object> <ContentsNodes> <Node id="4092"></Node> <Node id="4093"></Node> <Node id="4094"></Node> <Node id="11821"></Node> </ContentsNodes> <VariableAssignments> <VariableAssignment> <ID>70</ID> <Name>Model_Number</Name> <Value>300</Value> <ValueObject>0</ValueObject> <Style>-1</Style> <PublishPrompt>true</PublishPrompt> <IsVariantCriteria>false</IsVariantCriteria> </VariableAssignment> </VariableAssignments> <PrintByLine>Art. No.: <Article_Number></PrintByLine> <PrintVersion><Version></PrintVersion> <WebVersion><Version></WebVersion> </Book> <Topic wordcount="1"> <Object> <Description>Back Page</Description> <GUID>390099a7512b4ba79fa2245641714d47</GUID> <ID>6205</ID> <VariantParentID>4113</VariantParentID> </Object> <Headings></Headings> <RelatedGroups></RelatedGroups> <Text> <p id="254"><Version></p> </Text> <VariableAssignments></VariableAssignments> <PrintSuperHeading></PrintSuperHeading> <WebTitle></WebTitle> </Topic> </Objects> </AuthorIT>