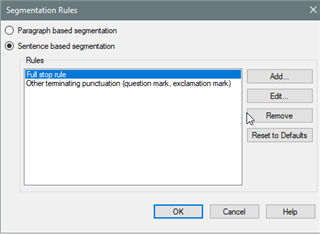
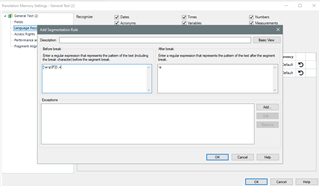
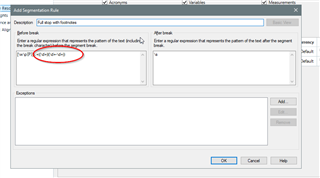
Some colleague translators are having segmentation problems when they work with note superscript numbers at the end of a sentence. They end up with several sentences together in the same segment that should had been segmented after the superscript number. Some translators end up fragmenting all those segments manually in the Editor, while others modify the original document before creating their project in Studio and move the punctuation after the note superscript number to avoid this kind of segmentation problem. Both methods are very time-consuming. How can the segmentation rules be modified to deal with this problem? Is there any other way to solve it? Thanks in advance.
Example:
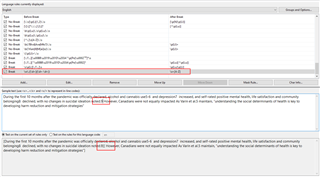
During the first 10 months after the pandemic was officially declared, alcohol and cannabis use5-6 [no problem here] and depression7 [no problem here] increased, and self-rated positive mental health, life satisfaction and community belonging8 [no problem here] declined, with no changes in suicidal ideation noted.9 [should have been segmented] However, Canadians were not equally impacted. As Varin et al.5 [no problem here; should not be segmented] maintain, “understanding the social determinants of health is key to developing harm reduction and mitigation strategies.”


Generated Image Alt-Text
[edited by: Trados AI at 3:48 AM (GMT 0) on 29 Feb 2024]