Hi,
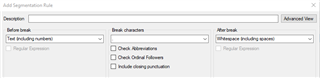
I have an issue with segmentation. In Finnish, ordinals are typed with a number followed by a full stop (eg. 1st = 1.) We have created an exception for this in the full stop rule, and it works fine (Before break \d\.+, After break \s).
However, as a result, there is now a segment break when a sentence ends in a number. How can I prevent this? I have tried to create a rule that would consider lower- and upper-case letters (as ordinals are mostly followed by a small-case letter), but I have had no luck with this.
Example sentences (pretending to be in Finnish):
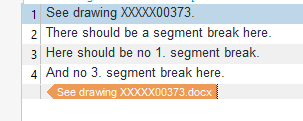
See drawing XXXXX00373. There should be a segment break here.
Here should be no 1. segment break. And no 3. segment break here.
Could anyone help me with this, please? Thanks!
BR,
-Elina.