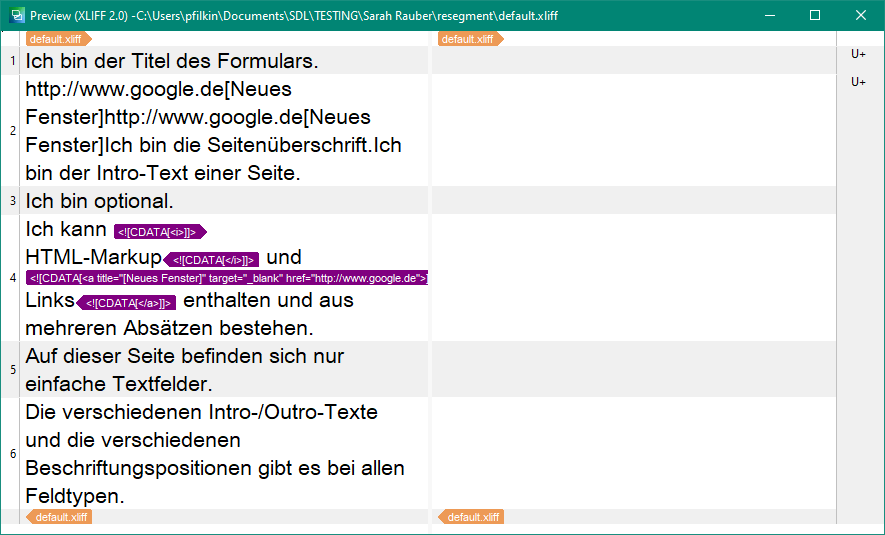
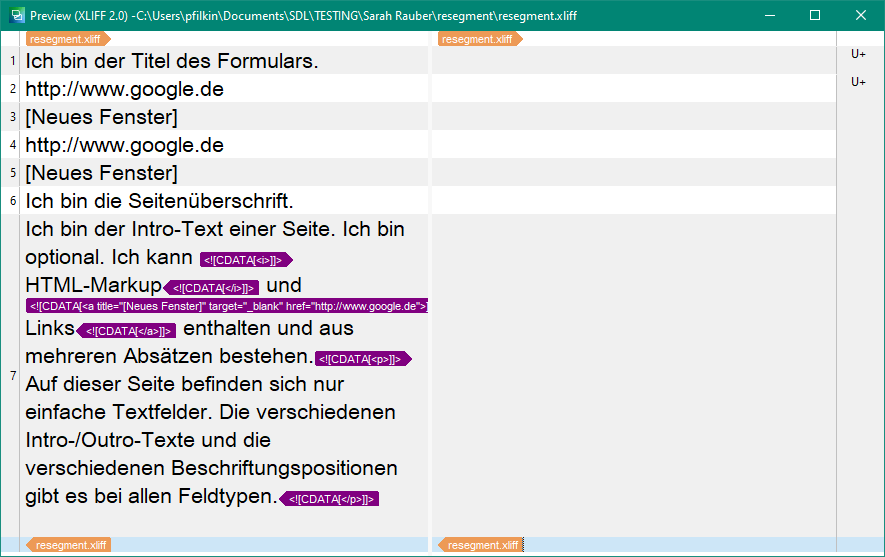
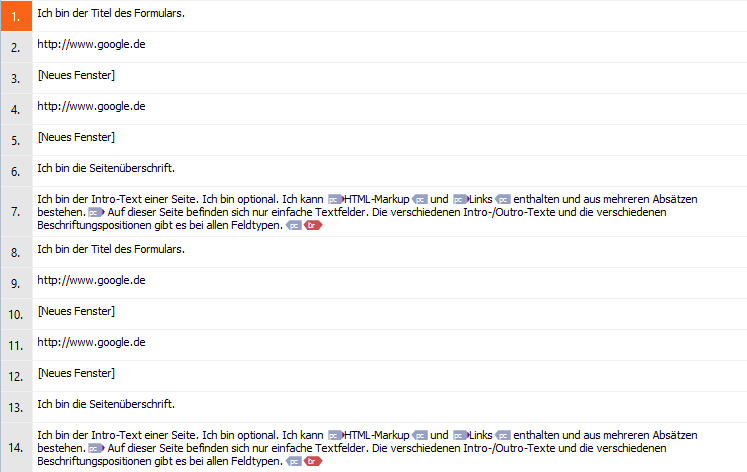
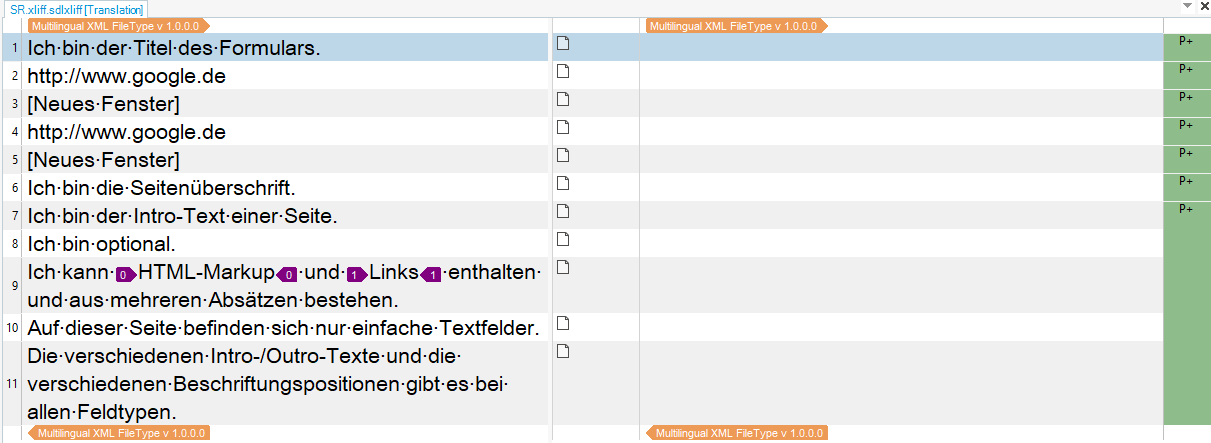
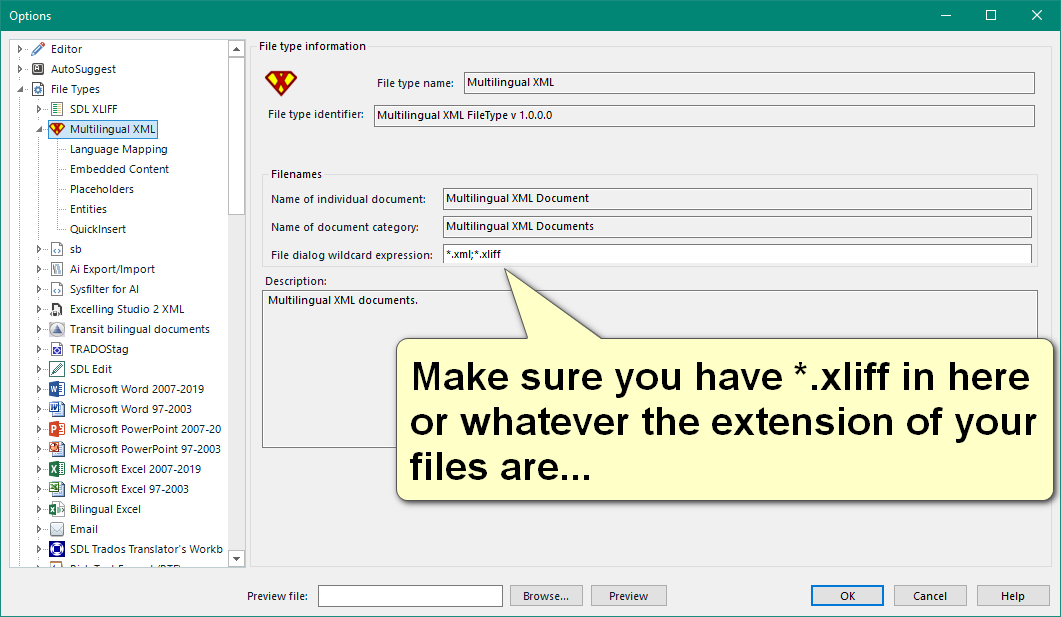
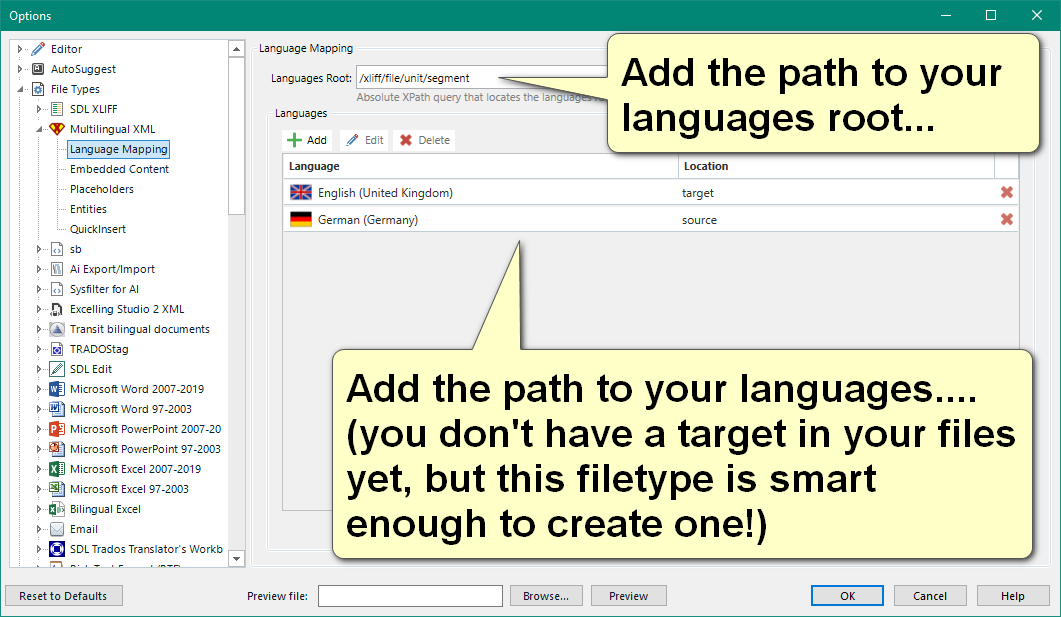
I have a problem when importing a file with the xliff 2.0 filetype in Studio 2021.
The file itself is fine. The import in memoq for example works absolutely fine.
in Studio, there is a problem with the segmentation. All sentences in one segment:

I guess this is a bug. Any comments here?
Generated Image Alt-Text
[edited by: Trados AI at 5:45 AM (GMT 0) on 29 Feb 2024]