Hello There,
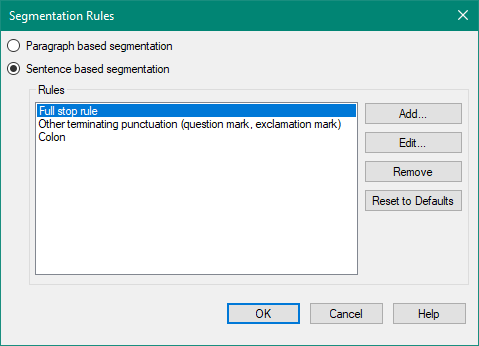
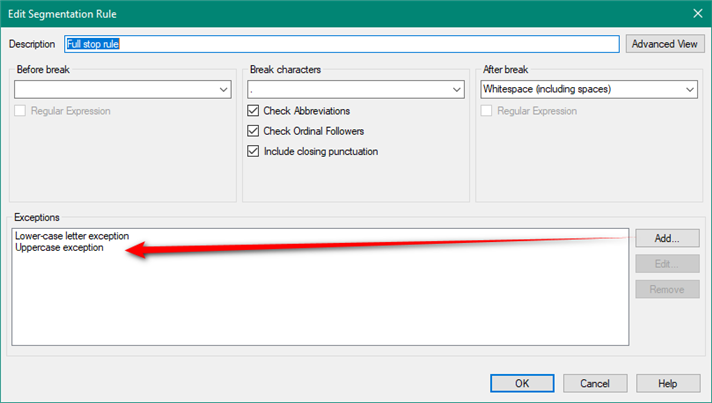
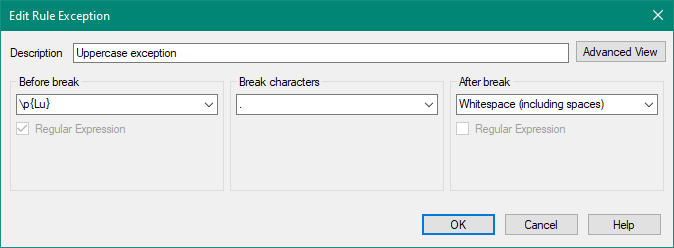
I have long sentences that contains punctuations. So, the sentences are automatically split into segments because they contain full stops. I want Trados to ignore these punctuations and keep the sentence as it is in one segment.
for example, this below sentence has got full stops. So, Trados break the sentence after each full stop and put new segment.
| 72% NYLON. 18% POLYESTER. 10% ELASTANE/SPANDEX. MACHINE WASHABLE. MODEL WEARS SIZE S. |
So, I need the sentence to be in one segment in order to translate it as one sentence.
Thanks