Hello everyone,
I have an issue in Studio/TM for a project I am working on.
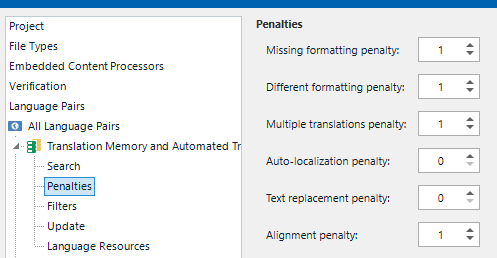
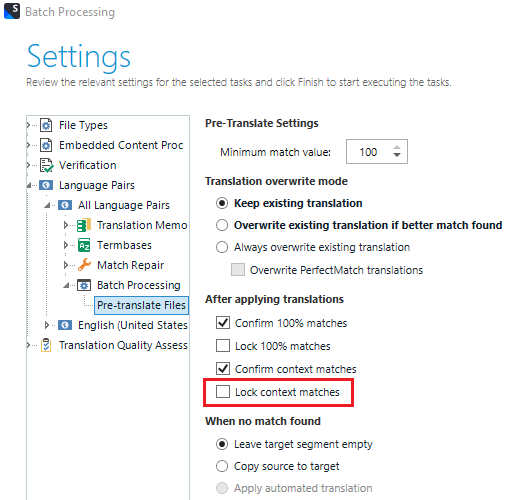
After creating a Studio project, usually some segments have translations from TM, but I found out that in some segments, there are different entries from TM and in TM message, it says "Different Target in Translation Memory". Even though these segments are different from TM, it's locked (I set up the studio to lock for CM during pre-translation) with CM status.
In the end, a segment which is different from TM is locked and set to CM.
Is this something to do with my Studio settings? Could you please check how I can avoid this and simply use the TM?
I attached one image.
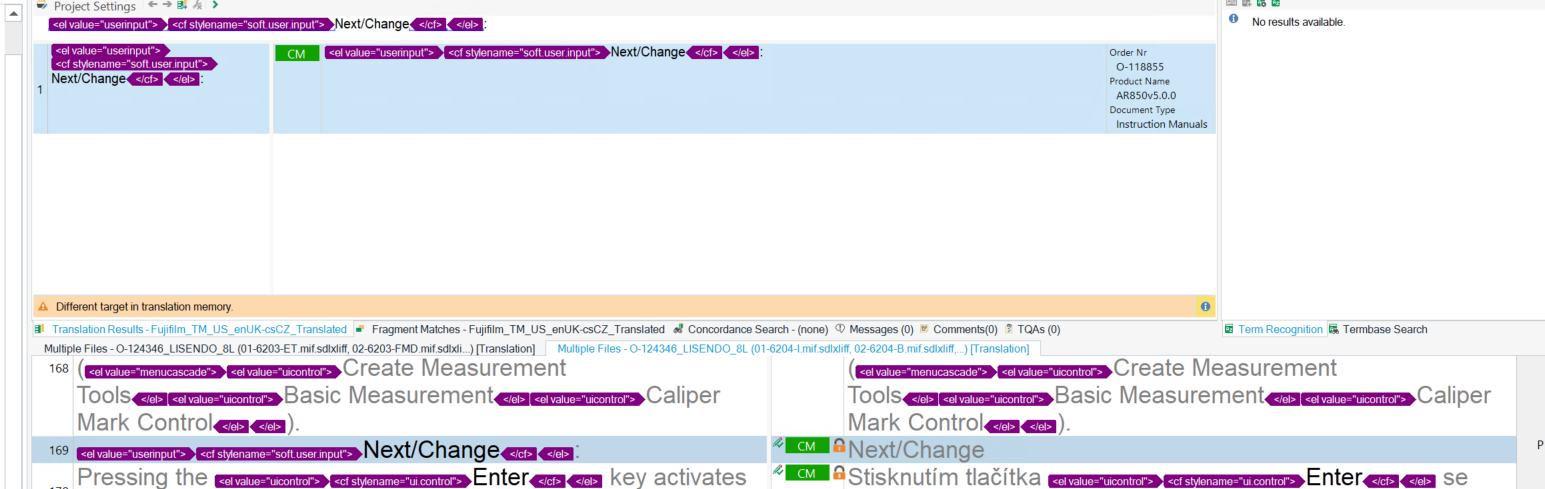
Generated Image Alt-Text
[edited by: Trados AI at 10:15 AM (GMT 0) on 29 Feb 2024]