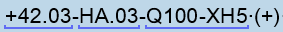Dear Community:
I often have to deal documents that contain lots of numbers and alphanumeric combinations. And Trados always changes something. I use regex to filter the segments containing ONLY these "non-translatables", and it works quite good (though some combination are still not included, the topic for my next thread:). So, where filter can be applied, the issue easy to fix.
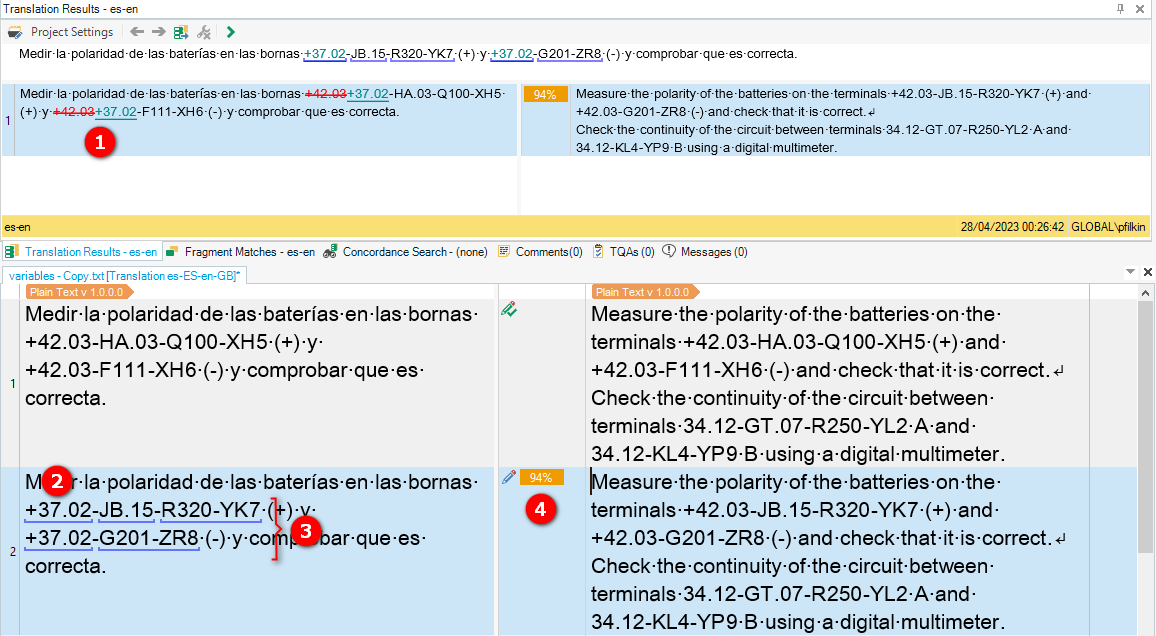
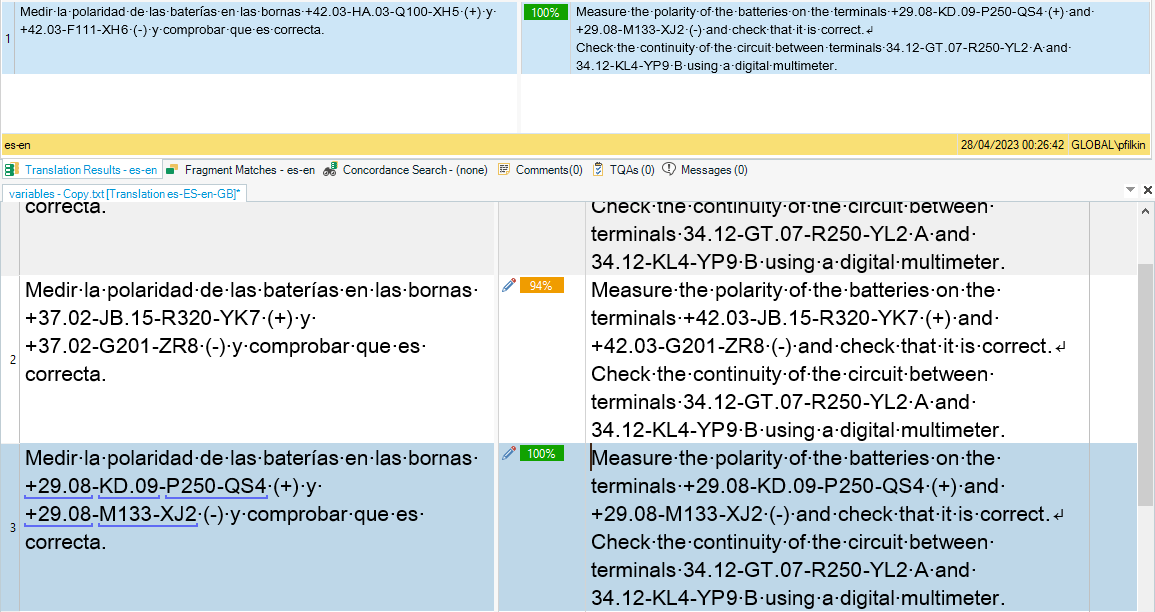
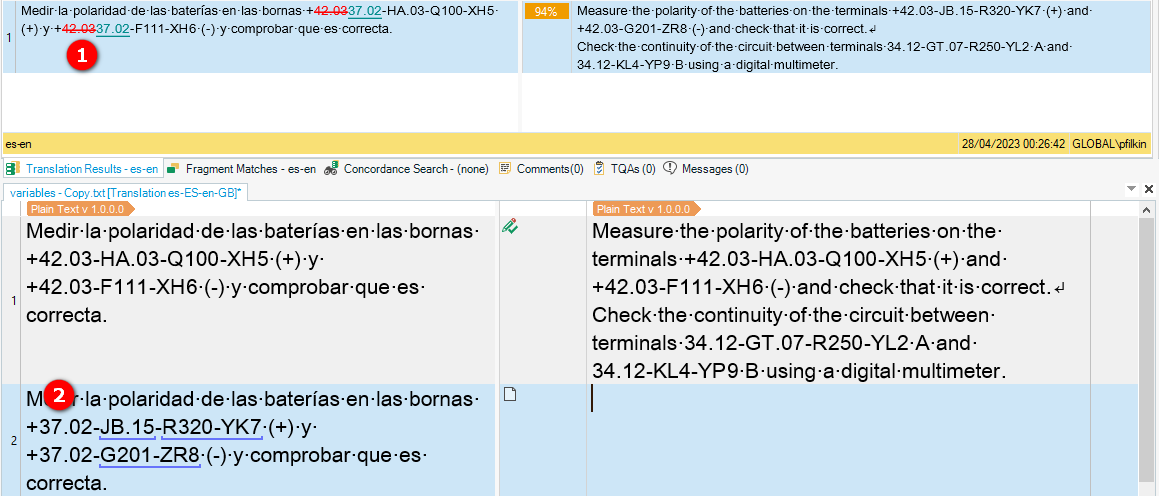
However, many text segments contain these alphanumerical combinations, for example: "Medir la polaridad de las baterías en las bornas +42.03-HA.03-Q100-XH5 (+) y +42.03-F111-XH6 (-) y comprobar que es correcta." When looking through the pretranslated results, errors are found in 95% of cases, Trados changes a number/numbers or a symbol.
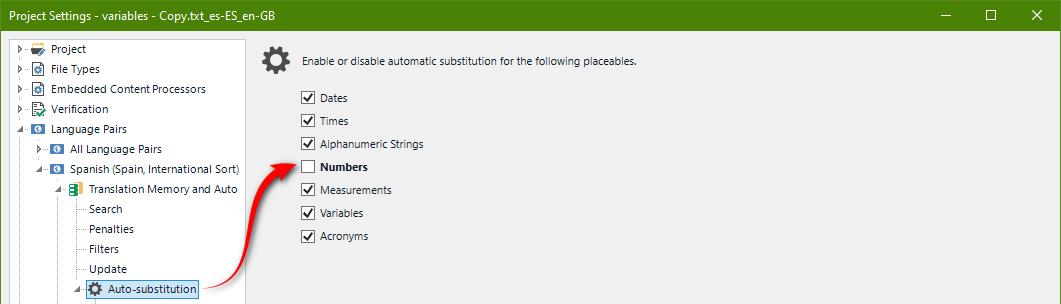
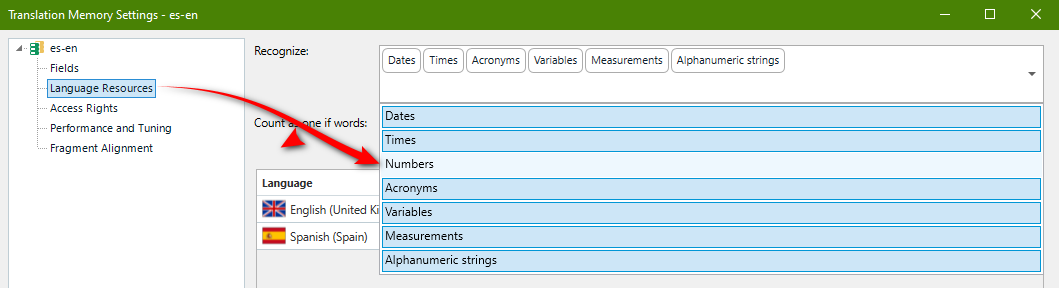
So to avoid this I usually deactivate the automatic replacement of all these numbers and variables in the memory settings of a particular project:
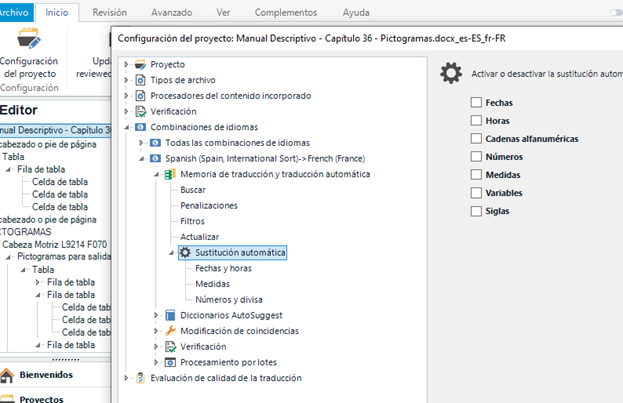
However, this is only applicable to this particular project, and cannot be changed from the General settings of Studio. I mean, I did the same here (actually it led me to the same list of TMs):
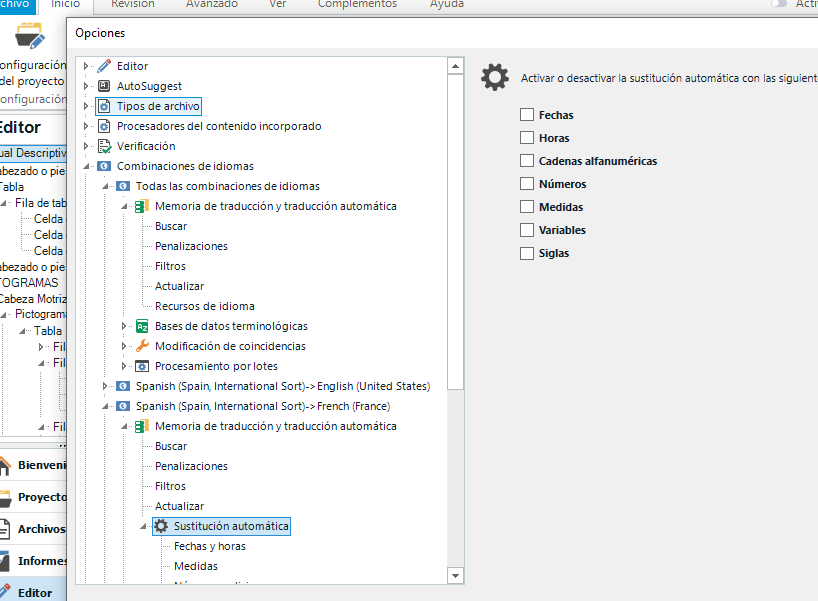
But the result was: if the varibles are unticked from the project configurations but remain activated in the general settings, Trados stops "recognizing" them, however, if they are deactivated in the general settings but activated in those of a particular project, Trados sees them.
Can anyone explain how it works? Because what I do is disconnect this automatic replacement at the project creation stage. And I would like to define this feature for all my translation projects
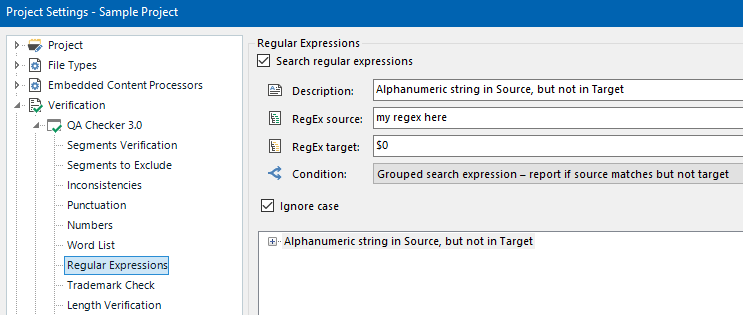
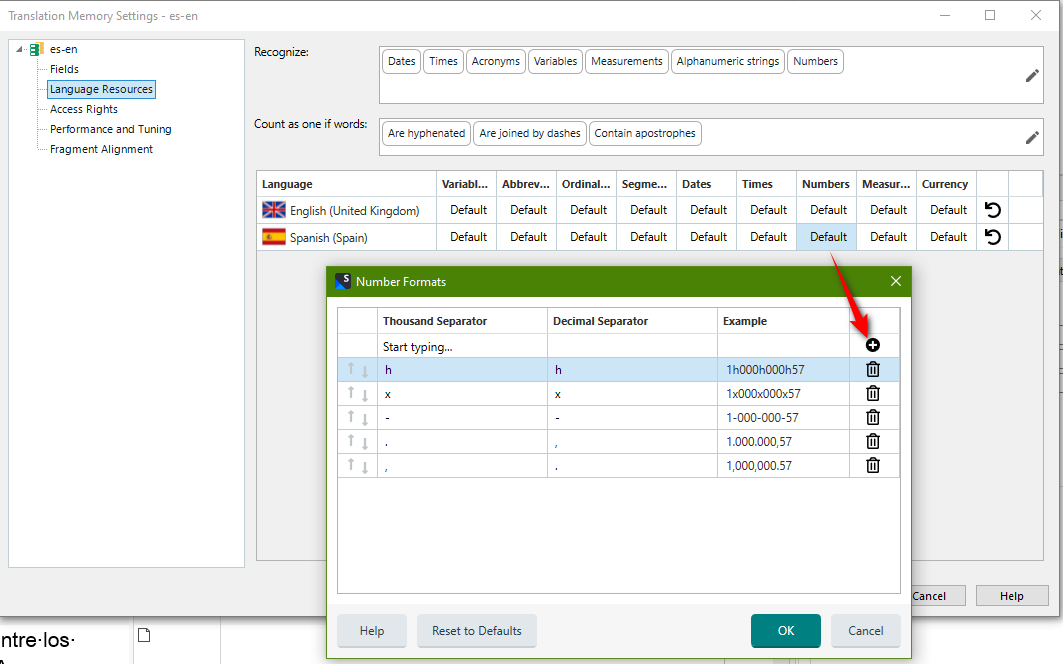
And then another question: what do "variables" mean in the list of variables?:)
To me, numbers and dates ARE variables...however, if I choose to deactivate the Variables option only, Trados still reads all this stuff.
Thanks in advance!!!
Generated Image Alt-Text
[edited by: Trados AI at 10:58 AM (GMT 0) on 29 Feb 2024]